
NLP. Основы. Техники. Саморазвитие. Часть 1 / Хабр
Привет! Меня зовут Иван Смуров, и я возглавляю группу исследований в области NLP в компании ABBYY. О том, чем занимается наша группа, можно почитать
здесь. Недавно я читал лекцию про Natural Language Processing (NLP) в
Школе глубокого обучения– это кружок при Физтех-школе прикладной математики и информатики МФТИ для старшеклассников, интересующихся программированием и математикой. Возможно, тезисы моей лекции кому-то пригодятся, поэтому поделюсь ими с Хабром.
Поскольку за один раз все объять не получится, разделим статью на две части. Сегодня я расскажу о том, как нейросети (или глубокое обучение) используются в NLP. Во второй части статьи мы сконцентрируемся на одной из самых распространенных задач NLP — задаче извлечения именованных сущностей (Named-entity recognition, NER) и разберем подробно архитектуры ее решений.
Что такое NLP?
Это широкий круг задач по обработке текстов на естественном языке (т.
- Первая и самая исторически важная задача – это машинный перевод. Ей занимаются очень давно, и есть огромный прогресс. Но задача получения полностью автоматического перевода высокого качества (FAHQMT) так и остается нерешенной. Это в каком-то смысле мотор NLP, одна из самых больших задач, которой можно заниматься.
- Вторая задача — классификация текстов. Дан набор текстов, и задача – классифицировать эти тексты по категориям. Каким? Это вопрос к корпусу.
Первый и один из самых важных с практической точки зрения способов применения — классификация писем на спам и хам (не спам).
Другой классический вариант — многоклассовая классификация новостей по категориям (рубрикация) — внешняя политика, спорт, шапито и т. п. Или, допустим, вам приходят письма, и вы хотите отделить заказы из интернет-магазина от авиабилетов и броней отелей.
Третий классический вариант применения задачи текстовой классификации — сентиментный анализ. Например, классификация отзывов на положительные, отрицательные и нейтральные.
Поскольку возможных категорий, на которые можно делить тексты, можно придумать очень много, текстовая классификация является одной из самых популярных практических задач NLP. - Третья задача – извлечение именованных сущностей, NER. Мы выделяем в тексте участки, которые соответствуют заранее выбранному набору сущностей, например, надо найти в тексте все локации, персоны и организации. В тексте «Остап Бендер — директор конторы “Рога и Копыта”» вы должны понять, что Остап Бендер – это персона, а “Рога и Копыта”– это организация. Зачем эта задача нужна на практике и как ее решать, мы поговорим во второй части нашей статьи.
- С третьей задачей связана четвертая — задача извлечения фактов и отношений (relation extraction). Например, есть отношение работы (Occupation). Из текста «Остап Бендер — директор конторы “Рога и Копыта”» ясно, что наш герой связан профессиональными отношениями с “Рогами и Копытами”.
 То же самое можно сказать множеством других способов: «Контору “Рога и Копыта” возглавляет Остап Бендер», или «Остап Бендер прошел путь от простого сына лейтенанта Шмидта до главы конторы “Рога и Копыта” ». Эти предложения отличаются не только предикатом, но и структурой.
То же самое можно сказать множеством других способов: «Контору “Рога и Копыта” возглавляет Остап Бендер», или «Остап Бендер прошел путь от простого сына лейтенанта Шмидта до главы конторы “Рога и Копыта” ». Эти предложения отличаются не только предикатом, но и структурой. Примерами других часто выделяемых отношений являются отношения купли/продажи (Purchase and Sale), владения (Ownership), факт рождения с атрибутами — датой, местом и т. д. (Birth) и некоторые другие.
Задача кажется не имеющей очевидного практического применения, но, тем не менее, она используется при структуризации неструктурированной информации. Кроме того, это важно в вопросно-ответных и диалоговых системах, в поисковиках — всегда, когда вам нужно анализировать вопрос и понимать, к какому типу он относится, а также, какие ограничения есть на ответ.
- Две следующие задачи, возможно, самые хайповые. Это вопросно-ответные и диалоговые системы (чат-боты). Amazon Alexa, Алиса – это классические примеры диалоговых систем.
 Чтобы они нормально работали, должно быть решено много задач NLP. Например, текстовая классификация помогает определить, попадаем ли мы в один из сценариев goal-oriented чат-бота. Допустим, «вопрос о курсах валют». Relation extraction нужно для определения заполнителей шаблона сценария, а задача ведения диалога на общие темы (“болталки”) поможет нам в ситуации, когда мы не попали ни в один из сценариев.
Чтобы они нормально работали, должно быть решено много задач NLP. Например, текстовая классификация помогает определить, попадаем ли мы в один из сценариев goal-oriented чат-бота. Допустим, «вопрос о курсах валют». Relation extraction нужно для определения заполнителей шаблона сценария, а задача ведения диалога на общие темы (“болталки”) поможет нам в ситуации, когда мы не попали ни в один из сценариев. Вопросно-ответные системы — тоже понятная и полезная вещь. Вы задаете машине вопрос, машина ищет ответ на него в базе данных или корпусе текстов. Примерами таких систем могут являться IBM Watson или Wolfram Alpha.
- Еще один пример классической задачи NLP — саммаризация. Формулировка задачи простая — на вход система принимает текст большого размера, а выходом служит текст меньшего размера, каким-то образом отражающий содержание большого. Например, от машины требуется сгенерировать пересказ текста, его название или аннотацию.
- Еще одна популярная задача – argumentation mining, поиск обоснования в тексте.
 Вам приводят факт и текст, вам нужно найти обоснование данного факта в тексте.
Вам приводят факт и текст, вам нужно найти обоснование данного факта в тексте.
Это безусловно не весь список задач NLP. Их десятки. По большому счету, все, что можно делать с текстом на естественном языке, можно отнести к задачам NLP, просто перечисленные темы на слуху, и у них есть наиболее очевидные практические применения.
Почему решать задачи NLP сложно?
Формулировки задач не очень сложные, однако сами задачи вовсе не являются простыми, потому что мы работаем с естественным языком. Явления полисемии (многозначные слова имеют общий исходный смысл) и омонимии (разные по смыслу слова произносятся и пишутся одинаково) характерны для любого естественного языка. И если носитель русского хорошо понимает, что в
теплом приемемало общего с
боевым приемом, с одной стороны, и
теплым пивом, с другой, автоматической системе приходится долго этому учиться. Почему «
Press space bar to continue» лучше перевести скучным «
Для продолжения нажмите пробел», чем «
Бар космической прессы продолжит работу».
- Полисемия: остановка (процесс или здание), стол (организация или объект), дятел (птица или человек).
- Другим классическим примером сложности языка является местоименная анафора. Например, пусть нам дан текст «Дворник два часа мел снег, он был недоволен». Местоимение «он» может относиться как к дворнику, так и к снегу. По контексту мы легко понимаем, что он – это дворник, а не снег. Но добиться, чтобы компьютер это тоже легко понимал, непросто. Задача местоименной анафоры и сейчас решена не очень хорошо, активные попытки улучшить качество решений продолжаются.
- Еще одна дополнительная сложность – это эллипсис. Например, «Петя съел зеленое яблоко, а Маша – красное». Мы понимаем, что Маша съела красное яблоко. Тем не менее, добиться, чтобы машина тоже поняла это, непросто. Сейчас задача восстановления эллипсиса решается на крошечных корпусах (несколько сотен предложений), и на них качество полного восстановления откровенно слабое (порядка 0.
 5). Понятно, что для практических применений такое качество никуда не годится.
5). Понятно, что для практических применений такое качество никуда не годится.
Кстати, в этом году на конференции «
Диалог» состоятся дорожки и по анафоре, и по гэппингу (виду эллиписа) для русского языка. Для обеих задач были собраны корпуса объемом, в несколько раз превышающим объемы существующих на данный момент корпусов (причем, для гэппинга объем корпуса на порядок превосходит объемы корпусов не только для русского, но и вообще для всех языков). Если вы хотите поучаствовать в соревнованиях на этих корпусах,
жмите сюда (с регистрацией, но без смс).
Как решают задачи NLP
В отличие от обработки изображений, по NLP до сих пор можно встретить статьи, где описываются решения, использующие не нейросетки, а классические алгоритмы типа
SVMили
Xgboost, и показывающие результаты, не слишком сильно уступающие state-of-the-art решениям.
Тем не менее, несколько лет назад нейросети начали побеждать классические модели. Важно отметить, что для большинства задач решения на основе классических методов были уникальные, как правило, не похожие на решения других задач как по архитектуре, так и по тому, как происходит сбор и обработка признаков.
Однако нейросетевые архитектуры намного более общие. Архитектура самой сети, скорее всего, тоже отличается, но намного меньше, идет тенденция в сторону полной универсализации. Тем не менее, то, с какими признаками и как именно мы работаем, уже практически одинаково для большинства задач NLP. Отличаются только последние слои нейросеток. Таким образом, можно считать, что сформировался единый пайплайн NLP. Про то, как он устроен, мы сейчас расскажем подробнее.
Pipeline NLP
Этот способ работы с признаками, который более-менее одинаков для всех задач.
Когда речь идет о языке, основная единица, с которой мы работаем, это слово. Или более формально «токен». Мы используем этот термин, потому что не очень понятно, что такое 2128506 — это слово или нет? Ответ не очевиден. Токен обычно отделен от других токенов пробелами или знаками препинания. И как можно понять из сложностей, которые мы описали выше, очень важен контекст каждого токена. Есть разные подходы, но в 95% случаев таким контекстом, который рассматривается при работе модели, выступает предложение, включающее исходный токен.
Многие задачи вообще решаются на уровне предложения. Например, машинный перевод. Чаще всего, мы просто переводим одно предложение и никак не используем контекст более широкого уровня. Есть задачи, где это не так, например, диалоговые системы. Тут важно помнить, о чем систему спрашивали раньше, чтобы она могла ответить на вопросы. Тем не менее, предложение — тоже основная единица, с которой мы работаем.
Поэтому первые два шага пайплайна, которые выполняются практически для решения любых задач – это сегментация (деление текста на предложения) и токенизация (деление предложений на токены, то есть отдельные слова). Это делается несложными алгоритмами.
Дальше нужно вычислить признаки каждого токена. Как правило, это происходит в два этапа. Первый – вычислить контекстно-независимые признаки токена. Это набор признаков, которые никак не зависят от окружающих наш токен других слов. Обычные контекстно-независимые признаки – это:
- эмбеддинги
- символьные признаки
- дополнительные признаки, специальные для конкретной задачи или языка
Про эмбеддинги и символьные признаки мы поговорим подробно дальше (про символьные признаки — не сегодня, а во второй части нашей статьи), а пока давайте приведем возможные примеры дополнительных признаков.
Один из самых часто использующихся признаков — часть речи или POS-тег (part of speech). Такие признаки могут быть важны для решения многих задач, например задачи синтаксического парсинга. Для языков со сложной морфологией, типа русского языка, также важны морфологические признаки: например, в каком падеже стоит существительное, какой род у прилагательного. Из этого можно сделать разные выводы о структуре предложения. Также, морфология нужна для лемматизации (приведения слов к начальным формам), с помощью которой мы можем сократить размерность признакового пространства, и поэтому морфологический анализ активно используется для большинства задач NLP.
Когда мы решаем задачу, где важно взаимодействие между различными объектами (например, в задаче relation extraction или при создании вопросно-ответной системы), нам нужно многое знать про структуру предложения. Для этого нужен синтаксический разбор. В школе все делали разбор предложения на подлежащее, сказуемое, дополнение и др. Синтаксический разбор – это что-то в этом духе, но сложнее.
Еще одним примером дополнительного признака является позиция токена в тексте. Мы можем априори знать, что какая-то сущность чаще встречается в начале текста или наоборот в конце.
Все вместе – эмбеддинги, символьные и дополнительные признаки – формируют вектор признаков токена, который не зависит от контекста.
Контекстно-зависимые признаки
Контекстно-зависимые признаки токена — это набор признаков, который содержит информацию не только про сам токен, но и про его соседей. Есть разные способы вычислить эти признаки. В классических алгоритмах люди часто просто шли «окном»: брали несколько (например, три) токенов до исходного и несколько токенов после, а затем вычисляли все признаки в таком окне. Такой подход ненадежен, так как важная информация для анализа может находиться на расстоянии, превышающем окно, соответственно, мы можем что-то пропустить.
Поэтому сейчас все контекстно-зависимые признаки вычисляются на уровне предложения стандартным образом: с помощью двухсторонних рекуррентных нейросетей LSTM или GRU. Чтобы получить контекстно-зависимые признаки токена из контекстно-независимых, контекстно-независимые признаки всех токенов предложения подаются в Bidirectional RNN (одно- или несколько- слойный). Выход Bidirectional RNN в i-ый момент времени и является контекстно-зависимым признаком i-того токена, который содержит информацию как о предыдущих токенах (т.к. эта информация содержится в i-м значении прямого RNN), так и о последующих (т.к. эта информация содержится в соответствующем значении обратного RNN).
Чтобы получить контекстно-зависимые признаки токена из контекстно-независимых, контекстно-независимые признаки всех токенов предложения подаются в Bidirectional RNN (одно- или несколько- слойный). Выход Bidirectional RNN в i-ый момент времени и является контекстно-зависимым признаком i-того токена, который содержит информацию как о предыдущих токенах (т.к. эта информация содержится в i-м значении прямого RNN), так и о последующих (т.к. эта информация содержится в соответствующем значении обратного RNN).
Дальше для каждой отдельной задачи мы делаем что-то свое, но первые несколько слоев — вплоть до Bidirectional RNN можно использовать для практически любых задач.
Такой способ получения признаков и называется пайплайном NLP.
Стоит отметить, что в последние 2 года исследователи активно пытаются усовершенствовать пайплайн NLP — как с точки зрения быстродействия (например, transformer — архитектура, основанная на self-attention, не содержит в себе RNN и поэтому способна быстрее обучаться и применяться), так и с точки зрения используемых признаков (сейчас активно используют признаки на основе предобученных языковых моделей, например ELMo, или используют первые слои предобученной языковой модели и дообучают их на имеющемся для задачи корпусе — ULMFit, BERT).
Словоформенные эмбеддинги
Давайте подробнее разберем, что же такое эмбеддинг. Грубо говоря, эмбеддинг — это сжатое представление о контексте слова. Почему важно знать контекст слова? Потому что мы верим в дистрибутивную гипотезу — что похожие по смыслу слова употребляются в сходных контекстах.
Давайте теперь попытаемся дать строгое определение эмбеддинга. Эмбеддинг – это отображение из дискретного вектора категориальных признаков в непрерывный вектор с заранее заданной размерностью.
Каноничный пример эмбеддинга – это эмбеддинг слова (словоформенный эмбеддинг).
Что обычно выступает в роли дискретного вектора признаков? Булев вектор, соответствующий всевозможным значениям какой-то категории (например, все возможные части речи или все возможные слова из какого-то ограниченного словаря).
Для словоформенных эмбеддингов такой категорией обычно выступает индекс слова в словаре. Допустим, есть словарь размерностью 100 тысяч. Соответственно, каждое слово имеет дискретный вектор признаков – булев вектор размерности 100 тысяч, где на одном месте (индексе данного слова в нашем словаре) стоит единичка, а на остальных – нули.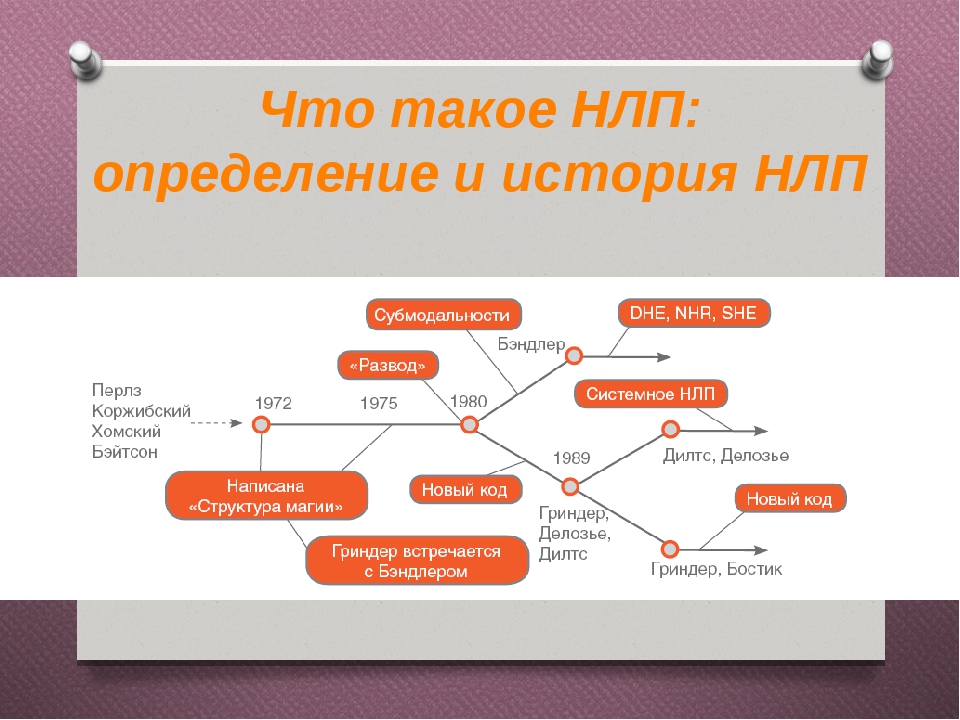
Почему мы хотим отображать наши дискретные вектора признаков в непрерывные заданной размерности? Потому что вектора размерностью 100 тысяч не очень удобно использовать для вычислений, а вот вектора целых чисел размерности 100, 200 или, например, 300, — намного удобнее.
В принципе, мы можем не пытаться накладывать никаких дополнительных ограничений на такое отображение. Но раз уж мы строим такое отображение, давайте попытаемся добиться, чтобы вектора похожих по смыслу слов также были в каком-то смысле близки. Это делается с помощью простой feed-forward нейросетки.
Обучение эмбеддингов
Как эмбеддинги обучаются? Мы пытаемся решить задачу восстановления слова по контексту (или наоборот, восстановления контекста по слову). В простейшем случае мы получаем на вход индекс в словаре предыдущего слова (булев вектор размерности словаря) и пытаемся определить индекс в словаре нашего слова. Делается это с помощью сетки с предельно простой архитектурой: два полносвязных слоя. Сначала идет полносвязный слой из булева вектора размерности словаря в скрытый слой размерности эмбеддинга (т.е. просто умножение булева вектора на матрицу нужной размерности). А потом наоборот, полносвязный слой с softmax из скрытого слоя размерности эмбеддинга в вектор размерности словаря. Благодаря функции активации softmax, мы получаем распределение вероятностей нашего слова и можем выбрать самый вероятный вариант.
Сначала идет полносвязный слой из булева вектора размерности словаря в скрытый слой размерности эмбеддинга (т.е. просто умножение булева вектора на матрицу нужной размерности). А потом наоборот, полносвязный слой с softmax из скрытого слоя размерности эмбеддинга в вектор размерности словаря. Благодаря функции активации softmax, мы получаем распределение вероятностей нашего слова и можем выбрать самый вероятный вариант.
Эмбеддингом i-го слова будет просто i-я строка в матрице перехода W.
В используемых на практике моделях архитектура сложнее, но ненамного. Главное отличие в том, что мы используем не один вектор из контекста для определения нашего слова, а несколько (например, все в окне размера 3). Несколько более популярным вариантом является ситуация, когда мы пытаемся предсказать не слово по контексту, а наоборот контекст по слову. Такой подход называется Skip-gram.
Давайте приведем пример применения задачи, которая решается во время обучения эмбеддингов (в варианте CBOW — предсказания слова по контексту).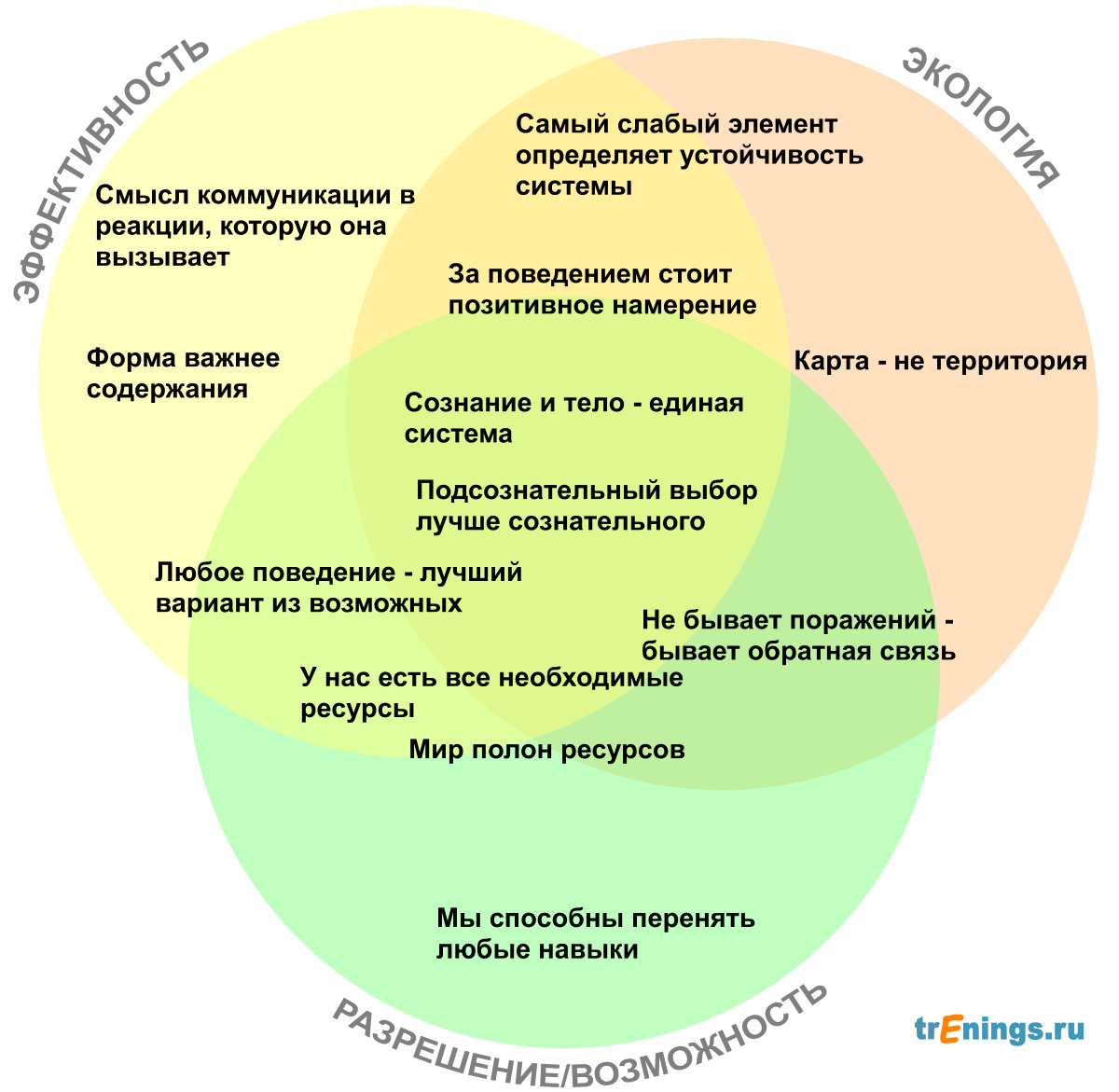 Например, пусть контекст токена состоит из 2 предыдущих слов. Если мы обучались на корпусе текстов про современную русскую литературу и контекст состоит из слов “поэт Марина”, то, скорее всего, самым вероятным следующим словом будет слово “Цветаева”.
Например, пусть контекст токена состоит из 2 предыдущих слов. Если мы обучались на корпусе текстов про современную русскую литературу и контекст состоит из слов “поэт Марина”, то, скорее всего, самым вероятным следующим словом будет слово “Цветаева”.
Подчеркнем еще раз, эмбеддинги только обучаются на задаче предсказания слова по контексту (или наоборот контекста по слову), а применять их можно в любых ситуациях, когда нам нужно вычислить признак токена.
Какой бы вариант мы ни выбрали, архитектура эмбеддингов очень несложная, и их большой плюс в том, что их можно обучать на неразмеченных данных (действительно, мы используем только информацию о соседях нашего токена, а для их определения нужен только сам текст). Получившиеся эмбеддинги — усредненный контекст именно по такому корпусу.
Эмбеддинги словоформ, как правило, обучаются на максимально большом и доступном для обучения корпусе. Обычно это вся Википедия на языке, потому что ее всю можно выкачать, и любые другие корпуса, которые получится достать.
Похожие соображения используются и при предобучении для современных архитектур, упомянутых выше — ELMo, ULMFit, BERT. Они тоже используют при обучении неразмеченные данные, и поэтому обучаются на максимально большом доступном корпусе (хотя сами архитектуры, конечно, сложнее, чем у классических эмбеддингов).
Зачем нужны эмбеддинги?
Как уже было упомянуто, для использования эмбеддингов есть 2 основные причины.
- Во-первых, мы уменьшаем размерность пространства признаков, потому что с непрерывными векторами размерностью несколько сотен работать намного удобнее, чем с признаками-булевыми векторами размерностью 100 тысяч. Уменьшение размерности признакового пространства – это очень важно: оно сказывается на быстродействии, это удобнее для обучения, и поэтому алгоритмы обучаются лучше.
- Во-вторых, учет близости элементов в исходном пространстве. Слова похожи друг на друга по-разному. И разные координаты эмбеддингов способны ловить эту схожесть.
 Приведу простой грубый и набивший всем оскомину пример. Эмбеддинг вполне способен уловить, что король отличается от королевы примерно так же, как мужчина от женщины. Или наоборот, король отличается от мужчины, как королева от женщины. Точно так же схожи связи разных стран со своими столицами. Хорошо обученная модель на достаточно большом корпусе способна понять, что Москва отличается от России тем же, чем Вашингтон от США.
Приведу простой грубый и набивший всем оскомину пример. Эмбеддинг вполне способен уловить, что король отличается от королевы примерно так же, как мужчина от женщины. Или наоборот, король отличается от мужчины, как королева от женщины. Точно так же схожи связи разных стран со своими столицами. Хорошо обученная модель на достаточно большом корпусе способна понять, что Москва отличается от России тем же, чем Вашингтон от США.
Но не нужно думать, что такая векторная арифметика работает надежно. В статье, где были введены эмбеддинги, были примеры, что Ангела относится к Меркель примерно так же, как Барак к Обаме, Николя к Саркози и Путин к Медведеву. Поэтому полагаться на эту арифметику не стоит, хотя это все равно важно, и компьютеру намного проще, когда он знает эту информацию, пусть она и содержит неточности.
В следующей части нашей статьи мы поговорим о задаче NER. Мы расскажем о том, что это за задача, зачем она нужна и какие подводные камни могут скрываться в ее решении. Мы расскажем подробно про то, как эту задачу решали с помощью классических методов, как ее стали решать с помощью нейросетей, и опишем современные архитектуры, созданные для ее решения.
Мы расскажем подробно про то, как эту задачу решали с помощью классических методов, как ее стали решать с помощью нейросетей, и опишем современные архитектуры, созданные для ее решения.
1. Основы НЛП. Что такое нейролингвистическое программирование (НЛП)?
В этом курсе мы поговорим о том, что такое НЛП. Нейролингвистическое программирование (НЛП) можно рассматривать как некую модель коммуникации между людьми, основой которой считают моделирование переживаний личностей, участвующих в этом взаимодействии.
НЛП считают молодой наукой. Его основы были заложены еще в 70-е годы прошлого века известными учеными в области психологии личности Ричардом Бендлером и Джоном Гриндером. Они больше внимания стали обращать на то, как и каким образом люди думают, каким образом происходит ими восприятие окружающего мира, что является мотивом их действий и какие действия они совершают благодаря этим мотивам.
Ученые выделили общее в процессах мышления и восприятия и объединили их в работающую систему — своего рода типовую модель поведения человека в зависимости от воспринимаемой им информации. На базе одной типовой модели были созданы другие, более позитивные и эффективные, которые позволяют контролировать наши мысли, изменять их, убирать те, которые нас ограничивают, формировать в нашем сознании необходимые убеждения, провоцировать нужные действия, которые будут постоянно продвигать нас к намеченным целям.
На базе одной типовой модели были созданы другие, более позитивные и эффективные, которые позволяют контролировать наши мысли, изменять их, убирать те, которые нас ограничивают, формировать в нашем сознании необходимые убеждения, провоцировать нужные действия, которые будут постоянно продвигать нас к намеченным целям.
Простыми словами нейролингвистическое программирование — что это такое? НЛП — это направление в психотерапии и практической психологии, не признаваемое академическим сообществом, основано на технике моделирования (копирования) вербального и невербального поведения людей, добившихся успеха в какой-либо области, и наборе связей между формами речи, движением глаз, тела и памятью.
Что такое нейролингвистичекое программирование (НЛП) и в чем его суть?
Приверженцы НЛП уверены, что всегда можно смоделировать поведение и жизненную модель успешного человека на других, внедряя в их сознание так называемое успешное поведение и мировоззрение, уделяя особое внимание особенностям коммуникации в проектируемых ситуациях.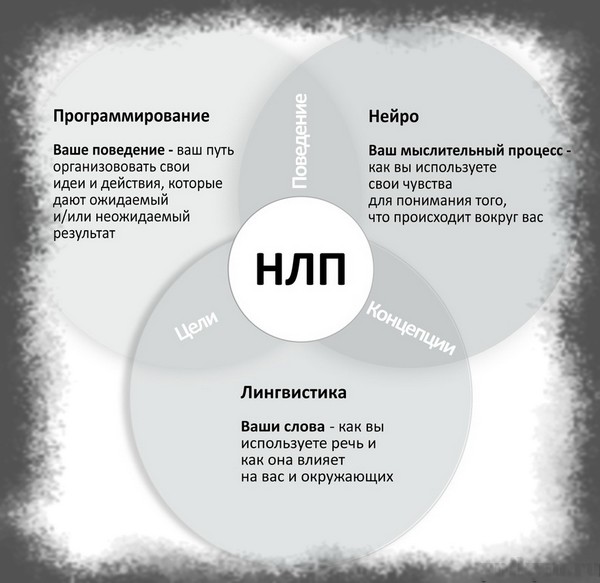 Подобные утверждения специалисты в области НЛП делают благодаря проведенным исследованиям в области психологии, психиатрии и психотерапии.
Подобные утверждения специалисты в области НЛП делают благодаря проведенным исследованиям в области психологии, психиатрии и психотерапии.
Многие специалисты используют определенные методы НЛП в своей практике и довольны их результатами в различных сферах деятельности. Кроме этого, эффективно применять методы НЛП в личной и профессиональной сферах могут и обычные люди, не получившие специального образования в области психологии.
Итак, нлп — это что в упрощенном виде? Особенности практикумов в том, что человек сразу получает готовый инструмент, показывающий, что и как нужно делать для достижения поставленных целей, выработке необходимых навыков и развития определенных способностей. А уже дальше вы можете проявлять свою индивидуальность и творческий подход, пользуясь полученным опытом и развивая собственную личность в таких направлениях, как образование, бизнес, коммуникации между людьми, личностный рост и другие.
Основной акцент во время применения практик НЛП делается на действия человека, а также его субъективное поведение и внутреннее отношение к происходящим событиям. На то, что люди говорят, обращают мало внимания. В результате наблюдений и понимания действий одаренного или успешного человека выстраивается так называемая модель необходимых действий. А вот результат внедренной модели действий считается достигнутым только тогда, когда он проявляется не одноразово, а систематически.
На то, что люди говорят, обращают мало внимания. В результате наблюдений и понимания действий одаренного или успешного человека выстраивается так называемая модель необходимых действий. А вот результат внедренной модели действий считается достигнутым только тогда, когда он проявляется не одноразово, а систематически.
Таким образом, задача коуча по нейро-лингвистическому программированию состоит в том, чтобы выделить необходимую модель поведения, сформулировать правила ее эффективного применения, проконтролировать результат ее применения, чтобы любой желающий мог ее применять на практике и не опасаться негативных последствий.
Если вы готовы меняться, применять новые методики и развивать новые навыки, вы научитесь делать много новых полезных вещей, в том числе и со своей личностью, научитесь развивать у себя ранее скрытые способности, о которых до этого и не подозревали, научитесь понимать людей и влиять на них поведение.
Где может быть полезно нейролингвистическое программирование?
Практика НЛП может быть полезна в любом направлении деятельности и при достижении любой цели, поставленной человеком. К примеру, обязательно изучение НЛП сотрудниками специальных служб, психиатрами, психологами, менеджерами, педагогами, специалистами PR-отделов и маркетологами. Кроме профессиональной деятельности, техники нейролингвистического программирования эффективно применяют и в личной жизни, и в достижении личной эффективности.
К примеру, обязательно изучение НЛП сотрудниками специальных служб, психиатрами, психологами, менеджерами, педагогами, специалистами PR-отделов и маркетологами. Кроме профессиональной деятельности, техники нейролингвистического программирования эффективно применяют и в личной жизни, и в достижении личной эффективности.
Надеемся, вы теперь понимаете: нлп — что это такое и что эта наука потенциально может вам дать. Применение техник может положительно сказаться на нормализации отношений в коллективе, развитии уверенности в себе и повышении самооценки, позволит усилить мотивацию и мобилизовать внутренние ресурсы на пути к цели, даст возможность лучше понимать поведение других людей, влиять на их мысли и поведение.
Наглядно поясняет что такое нейролингвистическое программирование презентация Красноярского центра НЛП. Посмотрите ее и вы все поймете:
Следующие статьи курса:
2. Как устанавливать контакт с людьми с помощью репрезентативной системы?
3. Принципы успешного общения. Референтная система.
4. Как читать невербальные реакции собеседника?
5. Как использовать «стереотип кавычек» при общении?
6. Как избавиться от депрессивного состояния с помощью НЛП?
НЛП — основы технологии и методы влияния на человека
Время чтения 7 минут
НЛП методы воздействия на человека относятся к разделу психотерапии. Другими словами — это взаимодействие речевых механизмов и человеческой психики. Его также называют нейролингвистическим программированием. Это разновидность суггестивного воздействия. Оно происходит через внушение на движение и мысли человека. Далее постараемся разобраться, как работают НЛП техники.
<<Оглавление>>
Из чего состоит НЛП
НЛП методы воздействия относятся к разделу нейролингвистического программирования. Посредством его устанавливается связь индивида с его подсознанием. Внутри человека есть богатые скрытые ресурсы. Не каждая личность умеет ими пользоваться.
Посредством его устанавливается связь индивида с его подсознанием. Внутри человека есть богатые скрытые ресурсы. Не каждая личность умеет ими пользоваться.
Благодаря доступу к невидимым ресурсам извлекается информация из подсознания. Она доставляется в сознательную часть человеческой психики. Лучшие техники НЛП могут работать по позитивному и негативному принципу. В бессознательную сферу происходит закладывание стереотипных мыслей о восприятии внешнего мира. К примеру, у индивида формируется мнение об устройстве мира, способах получения информации, правильном поведении. Так на психику можно воздействовать как на пользу личности, так и нанести ей урон. Это внешняя нервная деятельность человеческого организма.
Основа усвоения информации психикой делится на следующие системы:
- этап восприятия данных;
- обработка сведений;
- систематизация и хранение.
НЛП методы воздействия на человека имеют определенные принципы. Они могут способствовать повышению человеческой эффективности.
Они могут способствовать повышению человеческой эффективности.
Принято выделять следующие факторы:
- При согласованности или рапорте происходит существование с самим собой и окружающим миром. Достаточно признания факта наличия в мире определенных явлений.
- При ясных представлениях появляется результативность. Она может касаться конкретной ситуации или процесса. Важно при этом иметь четкость в сознании, однозначное понимание.
- Внимательность помогает достигать результат. Чувства должны быть открытыми, это ускоряет движение к намеченной цели.
- При гибкости в подходах можно умело достигать поставленных задач.
Таким образом, НЛП методы воздействия на человека способны менять его сознание. Для этого необходимы определенные как внешние, так и внутренние настройки.
Почему работают убеждения
НЛП методы воздействия на человека относятся к высшим логическим уровням разума. Такие ценности находятся в глубине сознания, они далеко не всегда понятны обывателю. Часто такая информация мотивирует, побуждает к действиям. Важно ответить самому себе на вопросы в отношении того, почему я это делаю, почему это так ценно для меня.
Часто такая информация мотивирует, побуждает к действиям. Важно ответить самому себе на вопросы в отношении того, почему я это делаю, почему это так ценно для меня.
На людей постоянно влияют убеждения. Некоторые склонны к тому, чтобы отказывать от хороших возможностей, которые могут в значительной степени улучшить их жизнь. Ими управляют подсознательные процессы, они не всегда могут распознаваться разумом.
Часто индивид убеждает окружающих людей и себя самого в правильности определенного утверждения. Нередко можно услышать обвинения внешних обстоятельств, друзей, знакомых в случившихся ситуациях. Человек перекладывает ответственность на все и на всех вокруг, но только не на себя.
Самая важная проблема кроется внутри человека. За все процессы отвечает его подсознание. Именно оно дает команды, побуждает к действиям, иногда даже формирует мысли. В подсознании хранятся шаблоны, установки, знаки. Они не всегда помогают в жизни, а могут наоборот приводить в тупик.
Человеческий мозг выдает любые ему удобные формулировки, приводит доводы, и тем самым еще больше запутывает своего владельца. Приемы НЛП воздействуют на личность, проникают внутрь его тонкой материи.
Достаточно несколько раз в день повторять одну и ту же фразу в утвердительной форме. Реальность не заставит себя ждать. Благодаря НЛП может произойти воздействие на человека. К примеру, по такой схеме формируются позитивные установки. Важно перед началом работы с убеждениями разобраться с тем, какие из них ведут к успеху, а какие выступают в качестве разрушающих маятников.
Большинство убеждений у человека формируются в детском возрасте.
Они отпечатываются на уровне подсознания. Пережитые неудачи становятся опытом, некоторые люди перестают верить в свои силы, считают, что в жизни ничего нельзя изменить. В таких ситуациях стоит некоторое время понаблюдать за самим собой, за своими мыслями. Нужно понять, что именно мотивирует принимать те или иные решения, что не дает действовать. Можно на листе бумаги фиксировать фразы, которые выдаются на уровне подсознания, а после работать с ними. Речевой аппарат, как правило, становится своеобразным зеркалом человеческого мышления. Наблюдая за словами можно понять, что именно выступает ограничителями.
Совершенно не обязательно посещать НЛП тренинг, иногда достаточно завести дневник, куда записывать все свои мысли. Через несколько дней к ним можно вернуться, подчеркнуть все фразы, которые воздействуют на реальность, побуждают к действиям и решениям. Стоит проработать каждый из тезисов, написать к нему еще несколько вариантов развития событий. Можно разобрать свои страхи и наоборот понять, что именно делает счастливым и доставляет удовольствие.
Влияние: основы технологии
При помощи нейролингвистического программирования происходит воздействие на мышление. Это значит, что нет никакой сложности в том, чтобы управлять собой и своей жизнью. Обучение НЛП также позволяет воздействовать на других людей. Нет никакой разницы в том, чтобы работать с информационным полем своей психики и психики другого человека.
К ценным навыкам обычно относят умение убеждать людей, оказывать на них влияние. По этой причине стоит изучить НЛП методы воздействия на человека более подробно. Особенно такие способности необходимы для индивида, работающего в сфере управления. К примеру, НЛП технология пригодится для менеджера по продажам, политика, актера.
Нейролингвистическое программирование — это основа сферы маркетинга. Посредством таких методов происходит влияние на потенциального покупателя. К НЛП относятся не только приемы по скрытому управлению людьми.
Обратите внимание, к одной из самых ценных и в то же время простых техник является подстройка. Достаточно подстроиться под репрезентативную систему другого человека. Таким способом произойдет влияние на восприятие мира, откроется одобрение на уровне подсознания.
Подстройка происходит посредством жестов, позы и манеров речи. Собеседника можно завоевать с первых секунд при зрительном контакте. Техники и книги по НЛП помогают лучше распознавать окружающих людей, а значит более эффективно воздействовать на них.
Такими приемами зачастую пользуются средства массовой информации. НЛП методы воздействия на человека помогают управлять массами. К наиболее распространенным методам принято относить фокусы речи. Они быстрее налаживают контакт с собеседником, устанавливают с ним близкие отношения. Таким способом можно быстро добиться расположения человека, завоевать его доверие, стать другом.
НЛП фокусы
НЛП техники похожи по своей структуре на выступление иллюзиониста. Благодаря ярким костюма и игре света зритель отвлекается от сути. По такому же принципу работают языковые фокусы.
Некоторые думают, что в том чтобы слушать другого незнакомого человека нет ничего особенного. На самом деле на уровне подсознания возникает доверие, готовность выполнить просьбу или согласиться на предложение. Управление человеком на уровне подсознания применяется в знаменитых рекламных лозунгах. Нередко затрагивается уровень идентичности человека. Личность начинает себя ассоциировать с определенной целевой группой. Включаются подсознательные механизмы. Именно с этого момента стоит изучать НЛП для начинающих.
Включаются подсознательные механизмы. Именно с этого момента стоит изучать НЛП для начинающих.
Рассмотрим несколько примеров фокусов языка, что помогут облегчить управление людьми:
- Метод трех согласий. Схема основывается на инертности человеческой психики. Три раза нужно получить согласие от собеседника, не важно, каким именно способом. После получения третьего “да” собеседник может на все соглашаться.
- Метод иллюзии выбора по принципу НЛП. Он заключается в том, что человеку предлагается несколько важных путей выхода из ситуации. Таким способом уводят его внимание от истинных вещей. Способ воздействия на подсознательном уровне часто применяется у родителей по отношению к их детям.
- Слова-ловушки. К ним относятся такие выражения как “вы знаете” и “вы понимаете”. Благодаря таким словосочетаниям подсознание попадает в НЛП-ловушку.
Можно также использовать команды, чтобы были заключены в вопросах. Часто применяется такой речевой оборот как “чем…тем”. Обратите внимание, это первые признаки манипуляторов.
Обратите внимание, это первые признаки манипуляторов.
Именно так выглядит НЛП на каждый день. Для получения более развернутой информации можно изучить труды Майкла Холла, Боденхамера и Ковалева. Все они занимались техниками НЛП. К примеру, достаточно для начала прочесть книгу “77 техник НЛП”.
НЛП методы воздействия на человека безграничны. Сегодня невозможно определить точное количество техник воздействия на человеческое подсознание. Каждый день меняется реальность, вместе с ней движется человеческая психика. Такие техники помогают в управление чужими мыслями, решениями других людей. По такой схеме можно получить желаемое от окружающих.
Существует вопрос, можно ли не попасть под воздействие НЛП. Важно самому себе отвечать на вопрос, насколько мне необходима это вещь или это действие здесь и сейчас. Не стоит принимать решения очень быстро. Лучше отложить вопрос на неопределенное время. Стоит дождаться того, когда самосознание самостоятельно примет решение. Так мысли и действия будут более осознанными. Именно этим приемам учат читателя “77 лучших техник НЛП”.
Так мысли и действия будут более осознанными. Именно этим приемам учат читателя “77 лучших техник НЛП”.
Способы воздействия на человека
НЛП методы воздействия на человека позволяют манипулировать и управлять группами лиц и отдельными людьми. Такие практики доступны каждому.
Воздействие на индивида при помощи скрытых методов можно разделить на несколько этапов:
- Сперва происходит присоединение. Его можно получить при помощи зрительного контакта. Достаточно копировать поведение другого человека, например, его движения, дыхание и темп речи.
- Далее нужно несколько раз получить от своего собеседника согласие.
- В конце такой методики можно вместе с собеседником утвердительно кивать головой, если нужно, то делать паузы.
Как только произошла подстройка под изменение позы другого человека, его жестов и мимики, важно словить взгляд человека, темп его дыхания. Таким способом можно выиграть переговоры, стать лучшим собеседником.
Часто техники НЛП применяют в любовных отношениях. Нет никакой разницы, в какой именно сфере тестировать навыки. По такой технологии можно влюбить в себя мужчину или женщину. Технология НЛП позволяет манипулировать другими людьми, их чувствами.
Эффективность метода в первую очередь зависит от человека, который его применяет. Бывают случаи, когда собеседник не поддается воздействию. Это значит, что он хорошо работает со своим подсознанием и не допускает атак из внешнего мира.
Самая распространенная техника, благодаря которой можно завоевать своего партнера, это просто перенять его ценности. Достаточно включить зеркальность и поверить в это. Человеку свойственно любить себя самого, те дела, которыми он занимается, особенно если это хобби или вещи.
Знание техник НЛП может наделить человека безграничной властью. Вопрос только в том, каким образом он будет пользоваться ей. Такая техника оказывает влияние как в целом на толпу, так и на отдельного индивида. Важно понимать, каким именно должно получиться воздействие, должно ли оно иметь позитивные или негативные оттенки. Владелец схемы в полной мере может владеть своей жизнью и жизнью других людей. Наравне с этим не нужно забывать об ответственности, ведь каждое действие имеет последствия, в том числе соблазнение противоположного пола.
Важно понимать, каким именно должно получиться воздействие, должно ли оно иметь позитивные или негативные оттенки. Владелец схемы в полной мере может владеть своей жизнью и жизнью других людей. Наравне с этим не нужно забывать об ответственности, ведь каждое действие имеет последствия, в том числе соблазнение противоположного пола.
Тематика: НЛП
§ 1. Основы НЛП. Использование технологий нейролингвистического программирования в профессиональной деятельности специалиста по связям с общественностью
Похожие главы из других работ:
SEO как инструмент маркетинга
3.1 Основы SEO и его использование
Поисковая оптимизация (SEO) — это процесс работы над сайтом, его внутренними факторами, влияющими на ранжирование в поисковых системах — структурой, контентом, кодом HTML…
Анализ интернет-логистики на предприятии ООО «МИФЕТ»
1.1 Основы интернета
Что такое Internet? Интернет — это глобальная компьютерная сеть, в которой размещены различные службы или сервисы (E-mail, WordWideWeb, FTP, Usenet, Telnet и т. д.). Компьютерные сети предназначены для передачи данных, а телефонные сети и радиосети — для передачи голоса…
д.). Компьютерные сети предназначены для передачи данных, а телефонные сети и радиосети — для передачи голоса…
Ассортимент средств для ухода за полостью рта. Организация торговли данного отдела
2. Основы производства
Таблица 1. Состав зубной пасты Компонент Доля, % Глицерин дистиллированный ПК-94 и / или сорбитол 10,00-40,00 Синтетическая тонкодиспергированная аморфная двуокись кремния 5,00-25,00 Полиэтиленгликоль ПЭГ-12 или пропиленгликоль 2…
Медиастратегия продвижения новой торговой марки
1.1 Основы медиапланирования
В узком смысле медиапланирование можно понимать как процедуру формирования медиаплана, т. е. графика выходов рекламных сообщений в рамках рекламной кампании продукта/услуги. В более широком смысле это комплекс процедур с такими задачами…
Мерчандайзинг в работе аптеки
3. Основы мерчандайзинга
Театр начинается с вешалки, а аптека — с момента попадания ее вывески в поле зрения потенциального покупателя. Но вывеска не только должна информировать о местоположении аптечного предприятия. Ее цветовое решение…
Но вывеска не только должна информировать о местоположении аптечного предприятия. Ее цветовое решение…
Методологические основы маркетингового планирования на предприятии
1.1. Основы планирования
маркетинговый планирование услуга swot Планирование маркетинга в разных организациях осуществляется по-разному. Это касается содержания плана, длительности горизонта планирования, последовательности разработки, организации планирования. Так…
Организация розничной торговли
VI — Основы менеджмента
…
Организация розничной торговли
6.1 — Основы менеджмента
Менеджмент — означает создание, управление, контроль и максимально эффективное использование социально-экономических систем и моделей различных уровней…
Особенности маркетинга на примере компьютерного рынка
1. Основы маркетинга
1.1 Что же такое маркетинг?
Маркетинг — это удивительное сочетание строгой науки и виртуозного искусства эффективной работы на рынке. Маркетинг очень молод (ему еще нет и ста лет), но это не означает…
Маркетинг очень молод (ему еще нет и ста лет), но это не означает…
Паблик рилейшнз: значение, содержание, история становления
Основы коммуникации и ПР
…
Паблик рилейшнз: значение, содержание, история становления
4. Основы коммуникации
Определение коммуникации универсально для ПР, менеджмента и маркетинга. Коммуникации — это обмен информацией между двумя или более людьми. Значимость коммуникаций как сферы деятельности и области знаний в развитых странах растет…
Проблема сегментирования рынка в деятельности фирмы
1 Основы сегментирования
…
Сбытовая политика АПК «Зерно жизни»
1.1 Основы маркетинга в АПК
В современных условиях особое место в деятельности любого предприятия независимо от организационно-правовой формы, специализации и размеров отводится маркетингу как одному из важнейших элементов рыночного механизма хозяйствования…
Сегментация рынка «Московский Гобелен» по совокупности признаков
1.
 2 Основы сегментации
2 Основы сегментации
Сегментация рынка — углубление исследования рыночных возможностей предполагает необходимость членения рынков в зависимости от групп потребителей и потребительских свойств товаров…
Стратегия маркетинга на торговых ярмарках и выставках
1.1 Теоретические основы
В наш насыщенный информационный век акцент в коммерческой деятельности организации переноситься с производственных и распределительных аспектов на коммуникационные…
Книга «Основы нейролингвистического программирования. Введение в человеческое совершенство. Учебное пособие» Ковалев С В
Основы нейролингвистического программирования. Введение в человеческое совершенство. Учебное пособие
Нейролингвистическое программирование (НЛП) в настоящее время является одним из наиболее популярных направлений прикладной психологии. Область применения НЛП чрезвычайно широка и включает в себя психотерапию, педагогику, медицину, бизнес, маркетинг, рекламу, а также управленческий и политический консалтинг. В отличии от многих других практически ориентированных психологических дисциплин, Нейролингвистическое программирование обеспечивает быстрые изменения и решения проблем общества и человека, причем осуществляется все это в безусловном эффективном и экологичном режиме.
В отличии от многих других практически ориентированных психологических дисциплин, Нейролингвистическое программирование обеспечивает быстрые изменения и решения проблем общества и человека, причем осуществляется все это в безусловном эффективном и экологичном режиме.
- Издательство:
- Твои книги
- Год издания:
- 2011
- Место издания:
- Москва
- Язык текста:
- русский
- Тип обложки:
- Твердый переплет
- Формат:
- 84х108 1/32
- Размеры в мм (ДхШхВ):
- 200×130
- Вес:
-
270 гр.
- Страниц:
- 208
- Тираж:
- 2000 экз.
- Код товара:
- 574215
- ISBN:
- 978-5-903881-15-4
- В продаже с:
-
20.
07.2011
Нейролингвистическое программирование (НЛП) в настоящее время является одним из наиболее популярных направлений прикладной психологии. Область применения НЛП чрезвычайно широка и включает в себя психотерапию, педагогику, медицину, бизнес, маркетинг, рекламу, а также управленческий и политический консалтинг. В отличии от многих других практически ориентированных психологических дисциплин, Нейролингвистическое программирование обеспечивает быстрые изменения и решения проблем общества и человека, причем осуществляется все это в безусловном эффективном и экологичном режиме. Читать дальше…
НЛП нейролингвистическое программирование — основы, Реферат заказан в СТУДЕНТ ЦЕНТР
Термин «нейролингвистическое програмирование» (далее НЛП) произошел от трех названий наук, соединенных вместе:
Нейрология – изучает разум и то, как человек мыслит.
Лингвистика – исследует то, как человек использует язык и какое влияние оказывает язык на его личность.
Программирование – то, как мы строим наши действия, чтобы добиться желаемой цели.
Можно привести очень много определений НЛП, но лишь собрав их вместе каждый человек получает ясное представление об этой науке.
НЛП – это изучение структуры субъективного опыта.
НЛП – это стратегия ускоренного обучения, позволяющая определить и использовать параметры нашей собственной картины окружающего мира (Джон Гриндер).
НЛП – это гносеология, позволяющая нам возвратить потерянное – состояние благодати (Джон Гиндер).
НЛП – это теория, которая работает (Роберт Дилтс).
НЛП – это влияние языка на наш разум и последующее поведение.
НЛП – это системное изучение человеческого общения (Алекс фон Уде).
НЛП – это метод, позволяющий смоделировать совершенство, чтобы его
можно было повторить.
НЛП основывается на шести базовых принципах, которые называют основами НЛП:
1. Вы сами – это ваше эмоциональное состояние и уровень навыков.
Вы сами – это ваше эмоциональное состояние и уровень навыков.
Успех зависит от уровня навыков и имеющихся ресурсов в нашем распоряжении. Ресурсами НЛП (основной переменной) являются язык, физиология, эмоциональное состояние, ценности, убеждения и так далее. Чем более конгруэнтен человек, тем большего успеха он может достичь.
2. Предположения – это основа НЛП.
Предположение НЛП – это руководящие принципы, идеи и убеждения, которые предопределены заранее, то есть воспринимаются как должно и являются руководством к действию.
3. Взаимопонимание – это качество отношений.
Взаимопонимание – это качество отношений, проявляющееся через взаимное доверие и уважение к образу мыслей другого человека. Взаимопонимание можно строить на различных уровнях, но оно обязательно должно основываться на уважении и внимании к другим людям. Взаимопонимание строится постепенно и со временем перерастает в доверие.
4. Результаты – это знание того, что вы хотите.
Результаты – это знание того, что вы хотите.
Основной навык НЛП – это четкое понимание того, чего вы хотите, и способность выяснить у окружающих, чего хотят они. НЛП основывается на постоянном обдумывании результатов любой ситуации, чтобы человек всегда имел возможность действовать наиболее эффективно.
Результат- это то, чего вы хотите; задача – это то, что вы делаете ради достижения желаемой цели.
5. Обратная связь. Как понять, добились ли вы того, чего хотели?
Обратная связь означает внимание к собственным ощущениям – к тому, как вы смотрите, слушаете и чувствуете то, что с вами происходит. Чувства – единственный способ получить адекватную и достоверную обратную связь. Только они формируют контуры внутреннего мира.
6. Гибкость. Если ваши действия не приносят результата, нужно изменить образ действий.
Зная, чего человек хочет, и осознавая свои поступки человек может изменять стратегию, чтобы добиваться желаемого результата. И чем активнее человек будет действовать, тем выше шансы на успех. Чем больше выбора, тем лучше будут результаты.
И чем активнее человек будет действовать, тем выше шансы на успех. Чем больше выбора, тем лучше будут результаты.
НЛП – это саморазвитие и изменение. Сначала человек использует НЛП, чтобы работать над собой и стать таким, каким человек хочет и может быть.
Работая над собой, человек потом эффективно может помогать окружающим.
Для понимания этого момента можно взять на рассмотрения пример:
при объявлении техники безопасности на аварийный случай в самолете, бортпроводники предупреждают, что при понижении давления в салоне самолета, сверху автоматически выпадают кислородные маски, которые нужно прижать сначала к собственному лицу, прежде чем помогать окружающим. Потому что, если не прижать кислородную маску к лицу, то можно потерять сознание, и это приведет к тому, что пострадаем сами и не сможем помочь ничем другим людям.
Саморазвитие – это тоже самое. Чем больше можно узнать о самом себе, тем легче будет помочь окружающим.
НЛП учит не ставить интересы других людей превыше собственных.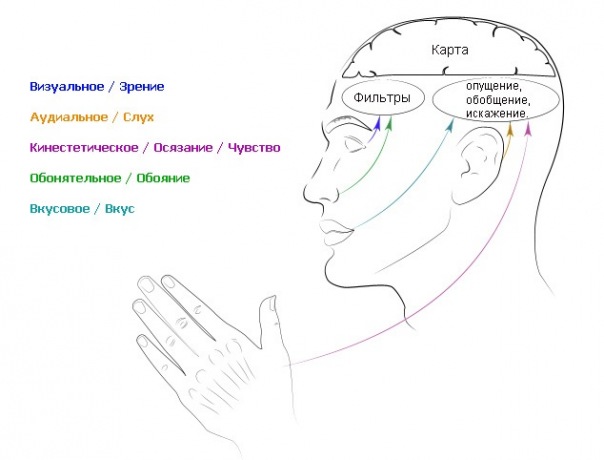
Навыки НЛП необходимы для саморазвития:
Способность выбирать собственное эмоциональное состояние.
Способность переключать мышление, группировать информацию восходящим, нисходящим или побочным образом.
Способность ориентироваться на результат.
Способность следовать за собой и т.д.
НЛП- определение, основы и причины эффективности. Основные пресуппозиции НЛП
Доклад
«НЛП- определение, основы и причины эффективности. Основные пресуппозиции НЛП »
Редькина Елена, 2 курс
«Социальная педагогика и самопознание»
Откуда взялось
название «Нейролингвистическое Программирование»?
«НЕЙРО» — это все то, что связано
с работой нервных клеток головного
мозга и их связей. Все наши пять
чувств: зрение, слух, обоняние, осязание
и вкус используются нами и в познании
окружающего мира и в нашем
мышлении. Поэтому все наше представление
об окружающем, все, что мы понимаем
как сознательную деятельность проходит
по этим нейронным связям в наш
мозг. «ЛИНГВИСТИЧЕСКОЕ» — эта часть
названия говорит нам о том, какую
роль в нашей жизни играет речь,
и в нашем мышлении и в общении
с окружающими нас людьми. НЛП
учит нас использовать нашу речь для
улучшения нашего образа мыслей и
для достижения успеха. «ПРОГРАММИРОВАНИЕ»
— указывает нам на то, что мы можем
программировать действия и свое мышление,
как программируется обычный компьютер.
«ЛИНГВИСТИЧЕСКОЕ» — эта часть
названия говорит нам о том, какую
роль в нашей жизни играет речь,
и в нашем мышлении и в общении
с окружающими нас людьми. НЛП
учит нас использовать нашу речь для
улучшения нашего образа мыслей и
для достижения успеха. «ПРОГРАММИРОВАНИЕ»
— указывает нам на то, что мы можем
программировать действия и свое мышление,
как программируется обычный компьютер.
В теоретическом плане нейролингвистическое
программирование определяется как многомерная
модель структуры и функции человеческого опыта.
НЛП описывает на одном уровне динамическое взаимодействие
нервной системы, физиологии, языка и поведенческого
программирования, то есть тех основных компонентов, которые
создают субъективный опыт. Будучи представленным
как процесс, НЛП представляет собой стратегию ускоренного
обучения и эффективного общения, причем бихевиориаль-
ная технология является его побочным продуктом. Последняя
включает набор фреймов, приемы и навыки развития системного
познания, гибкости и компетенции. НЛП также представляет
НЛП также представляет
собой особое отношение, в основе которого лежит
стройная система убеждений и предположений относительно
масштабов человеческих возможностей, процессов, общения
и изменений
В практическом аспекте нейролингвистическое программирование
— это искусство и наука о личном мастерстве.
Это практическое руководство, позволяющее добиться
тех результатов, к которым мы стремимся в этом мире.
Это описание того, что создает различия между выдающимся
и обычным, выдающимися и обычными людьми. И это система
приемов, техник и технологий, позволяющая использовать
колоссальные возможности человеческого Разума.
Смысл и предназначение НЛП можно выразить в виде
простой метафоры. Если вы покупаете какую-нибудь
сложную вещь — телевизор, компьютер и т. п., — то в обязательном
порядке требуете инструкцию по пользованию
этой самой вещью. Иначе вам просто не удастся воспользоваться
всеми возможностями, которые заложены в любом
сложном изделии. Но тогда как же жаль,
что Мать-
Но тогда как же жаль,
что Мать-
Природа, снабдив нас таким прекрасным инструментом,
как мозг, то ли забыла, то ли не захотела приложить к этому
изделию подробную инструкцию по пользованию. Соответственно,
нейролингвистическое
является наукой, которая как бы разрабатывает инструкции
по использованию возможностей человеческого мозга.
Инструкции по управлению мозгом — своим и чужим.
Причины эффективности
нейролингвистического
В настоящее время НЛП считается (даже
его оппонентами) одной из самых эффективных психотехнологий
личностных изменений. В качестве основных
причин этой эффективности специалисты по данной дисциплине
обычно называют следующие три:
-› стратегичность нейролингвистического программирования,
его нацеленность на результат;
-› опора НЛП на очень «экологичную» (то есть просто помогающую
жить) систему убеждений относительно
масштабов человеческих возможностей и многого
прочего;
-› ориентация в работе на всю или, по крайней мере, большую
часть потенциала человеческого мозга, заключенного
в Бессознательном. И использование
языка и
И использование
языка и
кодов, доступных и понятных этому самому бессознательному.
Рассмотрим все это более подробно.
Итак, во-первых, нейролингвистическое программирование
стратегично по самой своей сути. Безоговорочно нацелено
на результат. И всегда идет не от негатива (плохого),
а к позитиву (хорошему). Это только кажется, что разница
между этими последними «от» и «к» не очень-то существенна.
На самом деле она кардинальна. Избавиться от чего-
то вовсе не значит к чему-то прийти. Если вы воскресным
вечером после проведенного на природе уик-энда собираетесь
вернуться домой, вам не удастся сделать это,
просто идя от леса, в котором вы так хорошо провели свое
время. Вам обязательно нужно идти к остановке автобуса,
станции электрички или припрятанной неподалеку маши-
не. Самолет, летящий от аэродрома и не знающий конечной
точки своего маршрута — другого аэродрома, на котором
он сможет приземлиться, — летит в никуда: к аварийной
посадке где-нибудь в тайге. Да, человек
— это,
Да, человек
— это,
конечно же, не самолет. Но если он идет от чего-то, не
зная, к чему он собирается прийти, вероятность успеха
«путешествия» становится минимальной. Специалисты по
нейролингвистическому программированию, моделируя
эффективность и совершенство, давно уже установили, что
единственно действенным является именно движение к, а
не от; приближение к позитиву, а не удаление от негатива.
Так, в условиях нынешнего базара, который мы ошибочно
называем рыночной экономикой, миллионы людей занялись
бизнесом. Примерно восемьдесят процентов из них —
чтобы уйти от нищеты. И только двадцать — чтобы прийти
к богатству. Как вы думаете, кто из них добился большего
успеха и преуспел?
В качестве главной причины, по которой движение к
позитиву куда эффективней удаления от негатива,* энэлпе-‘
ры обычно указывают на своеобразную, но почему-то малоизвестную
многим особенность работы нашего мозга,
который как бы не понимает частицы не и заложенного в
ней момента отрицания. В результате
употребляющие это
В результате
употребляющие это
отрицание люди сплошь и рядом программируют себя с
точностью до наоборот. Например, сейчас, пожалуйста, не
думайте о хромой белой обезьяне. Ни под каким видом! Никоим
образом! И никак не меньше минуты! Получилось?
Вряд ли. Потому что для того, чтобы не думать об этой самой
мартышке или другой разновидности четвероруких,
вы сначала должны были о ней подумать. Как-то представить
ее, после чего — если вы, конечно же, были честны
перед самим собой, — она накрепко засела в вашем сознании.
А теперь, продолжая не думать о белой хромой обезьяне
(она опять появилась?), подумайте о розовом медведе.
Что, все? Обезьяна исчезла? Естественно. Но весь этот фокус
нужен был только для того, чтобы подчеркнуть единственное,
но колоссальной важности положение (идею). Что
уходя от чего-то, вы, как это ни странно, именно к этому и
приходите. Вы не хотите быть бедным? Как это понятно и
естественно! Но только лишь уходя от бедности, вы периодически,
непременно и непреложно думаете именно о ней —
о том, от чего вы уходите. И по сути программируете
свой
И по сути программируете
свой
мозг на поддержание и воспроизводство столь ненавистного
вам состояния, близкого к нищете.
Во-вторых, эффективность НЛП закономерно вытекает
из системы его базовых
Это очень интересная и стройная система убеждений
и посылок относительно масштабов человеческих
возможностей, процессов, общения и изменений. По мнению
энэлперов, личное обаяние, овладевайте знаниями,
отношения с другими людьми и творческий процесс зависят
от базовых убеждений человека. А базовые предположения
нейролингвистического программирования обеспечивают
успешность существования в этом мире. Чтобы
проверить эффективность пресуппозиций НЛП, специалисты
в этой области обычно рекомендуют действовать,
исходя из той предпосылки, что они верны, после чего
определить получаемый эффект (для того, чтобы узнать,
полезно ли то или иное, лучше всего попытаться использовать
его).
Приведем — пока без расшифровки и комментариев —
основные и дополнительные «убеждения» нейролингвистического
программирования.
Основные пресуппозиции НЛП
/. Наши представления о мире этим миром не являются
(карта — это не территория).
2. Модель мира другого
человека может в корне
от моей. И я обязан
уважать и учитывать эти
3. Сознание и тело — это часть одной и той же кибернетической
системы.
4. Весь наш жизненный опыт закодирован в нашей нервной
системе.
5. Субъективный опыт
состоит из визуальных образов,
чувств, вкусовых ощущений и запахов.
6. Смысл моего общения заключается в той реакции, которую
оно вызывает.
7. Не бывает поражений, существует только обратная
связь.
8. Любое поведение представляет собой выбор самого лучшего
варианта из имеющихся в настоящий момент.
9. Любое поведение имеет позитивную интенцию (исходное
положительное намерение).
10. Любое поведение привязано (адаптируется) или было привязано
к первоначальному окружению.
11. Каждый из нас располагает всеми ресурсами, которые
необходимы для достижения своих целей.
12. Вселенная, в которой мы живем, представляет собой
дружественную, изобилующую ресурсами, сферу.
Дополнительные пресуппозиции НЛП
1. Я тот, кто контролирует свой мозг и свои результаты.
2. Если это возможно в мире, это возможно и для меня.
3. Проблема — это
неверно сформулированное
4. Каждая ситуация содержит множество выборов. Поэтому
если нечто не работает, надо просто сделать
что-то другое.
5. Или я верю, что могу, или я ничего не могу.
6. Все, что можно детально представить, осуществимо.
7. Я могу все то, чего я действительно хочу.
Следует отметить, что пресуппозиции НЛП не столько
верны, сколько экологичны. Как вы, наверное, уже поняли,
в нейролингвистическом программировании вообще нет
понятий «истинно» и «ложно». Они давно заменены терминами
«экологично» (что значит «помогает жить в соответствии
с жизнью») и «неэкологично» (наоборот).
Однако главное здесь состоит в том, что пресуппозиции
НЛП очень важны для успешного осуществления ПК и
психотерапии. Э. Минделл, жена известнейшего специалиста’
по процессуальной психологии А. Минделла, была
одной из первых, кто применил термин «метанавык».
Этим словом она обозначила глубокие духовные качества,
убеждения, верования и принципы, которые проявляются
в повседневной жизни и работе психотерапевта. Именно
метанавыки создают во взаимодействии психотерапевта и
клиента некую чувственную атмосферу, в основе которой —
отношение к жизни, к природе и к развитию человека.
И если психотерапевт внутренне ненавидит жизнь, считает
природу людей патологически ущербной, а развитие человека
практически невозможным, он никогда не добьется
серьезного успеха в исцелении, сколь бы изощренные техники
не использовались в терапевтическом процессе. Ибо
без прочного фундамента позитивных метанавыков все эти
техники окажутся легковесными конструкциями, не выдерживающими
первого же столкновения с ре&тьностью
психических нарушений.
В качестве базовых ПК-пресуппозиций НЛП мы приводим
только некоторые, важнейшие в контексте психологического
консультирования и
учтите, что вы в обязательном порядке должны их понять и
принять. Как своеобразные восемь заповедей, в которые
нужно верить и которые следует обязательно выполнять, —
если, конечно, вы действительно хотите стать Мастером
нейролингвистического программирования.
— Каждая проблема имеет свое решение.
Существуют «Переменные среды», над которыми мы,
возможно, не властны. Но есть и «Переменные выбора», каковые
полностью в наших руках. И даже в нынешней не слишком
уютной жизни есть масса возможностей для того, чтобы
изменить ее к лучшему. Просто мы пока не видим этих
возможностей.
— Каждый уже имеет все, что ему необходимо.
У нас есть все ресурсы для того, чтобы быть всем, кем
угодно, или делать все, что угодно, — при условии, что мы
способны использовать эти ресурсы в нужный момент и в
нужной последовательности.
— Каждая ситуация имеет несколько выборов. Поэтому
если что-то не работает, сделайте это по-другому.
Если мы не достигли искомого результата неким пусть
даже единственно верным способом, надо попробовать полностью
изменить свой подход. Один и тот же способ действий
или манера поведения дают одни и те же результаты — часто
плачевные или неэкологичные. Иные же подходы могут
привести к желаемому.
— Проблемы и боль — это механизмы обратной связи.
Именно они дают нам информацию, в которой мы так нуждаемся.
Однако ни проблемы, ни боль не являются необходимыми
компонентами к изменению. Они могут быть лишь сигналом
к смене направления. Информацией о том, что мы идем куда-
то не туда. И может быть даже не ведаем о том, куда
идем. А тот, кто не знает куда идет, может зайти в тупик
почти всегда.
— Не существует поражений, есть только обратная
Основы обработки естественного языка
Введение
Согласно отраслевым оценкам, только 21% доступных данных представлены в структурированной форме. Данные генерируются, когда мы говорим, когда мы твитнем, когда отправляем сообщения в WhatsApp и при выполнении различных других действий. Большинство этих данных существует в текстовой форме, которая по своей природе очень неструктурирована.
Несмотря на наличие данных большого размера, информация, представленная в нем, не является напрямую доступной, если она не обрабатывается (читается и не понимается) вручную или не анализируется автоматизированной системой.Чтобы получить значительную и полезную информацию из текстовых данных, важно познакомиться с основами обработки естественного языка (NLP).
Примечание. Если вас больше интересует изучение концепций в аудио-визуальном формате, у нас есть вся эта статья, объясненная в видео ниже. Если нет, можете продолжить чтение.
В этой статье мы поговорим об основах различных методов, связанных с обработкой естественного языка.
Содержание
- Что такое корпус, жетоны и энграммы?
- Что такое токенизация?
- Что такое токенизация белого пространства?
- Что такое токенизация регулярных выражений?
- Что такое нормализация?
- Что такое стемминг?
- Что такое лемматизация?
- Часть речевых тегов в NLP
- Грамматика в НЛП и ее виды
- Что такое грамматика округа?
- Что такое грамматика зависимостей?
Начнем!
Что такое корпус, жетоны и энграммы?
Corpus определяется как набор текстовых документов, например, набор данных, содержащий новости, является корпусом, или твиты, содержащие данные Twitter, являются корпусом.Таким образом, корпус состоит из документов, документы состоят из абзацев, абзацы состоят из предложений, а предложения содержат более мелкие единицы, которые называются токенами .
токенов могут быть словами, фразами или энграммами, а энграммы определяются как группа из n слов вместе.
Например, рассмотрим данное предложение —
«Я люблю свой телефон».
В этом предложении униграммы (n = 1) таковы: я, любовь моя, телефон
Диаграммы (n = 2): Я люблю, люблю свой, мой телефон
И триграммы (n = 3): Я люблю свой, люблю свой телефон
Итак, юниграммы представляют одно слово, диаграммы представляют два слова вместе, а триграммы представляют три слова вместе.
2. Что такое токенизация?
Давайте теперь обсудим токенизацию. Токенизация — это процесс разделения текстового объекта на более мелкие части, которые также называются токенами. Примерами жетонов могут быть слова, числа, инграммы или даже символы. Наиболее часто используемый процесс токенизации — это Токенизация белого пространства .
2.1 Что такое токенизация белого пространства?
Также известен как токенизация униграмм. В этом процессе весь текст разбивается на слова, отделяя их от пробелов.
Например, в предложении — «Я поехал в Нью-Йорк поиграть в футбол».
Это будет разделено на следующие жетоны: «Я», «пошел», «в», «Нью-Йорк», «в», «играть», «футбол».
Обратите внимание, , что «Нью-Йорк» не разделяется дальше, потому что процесс токенизации был основан только на пробелах.
2.2 Что такое токенизация регулярного выражения?
Другой тип процесса токенизации — это Токенизация регулярного выражения, , в котором для получения токенов используется шаблон регулярного выражения.Например, рассмотрим следующую строку, содержащую несколько разделителей, таких как запятая, точка с запятой и пробел.
Предложение = «Футбол, крикет; Гольф Теннис » re.split (r ’[;, \ s]’, предложение
жетонов = «Футбол», «Крикет», «Гольф», «Теннис»
Используя регулярное выражение, мы можем разделить текст, передав шаблон разделения.
Токенизация может быть выполнена на уровне предложения, на мировом уровне или даже на уровне персонажа.
3. Что такое нормализация?
Следующий метод — Нормализация . В области лингвистики и НЛП морфема определяется как базовая форма слова. Токен обычно состоит из двух компонентов: морфем, которые являются базовой формой слова, и флективных форм, которые, по сути, представляют собой суффиксы и префиксы, добавляемые к морфемам.
Например, рассмотрим слово Антинационалист,
, который состоит из A nti и ist как флективных форм и national как морфемы. Нормализация — это процесс преобразования токена в его базовую форму. В процессе нормализации изгиб слова удаляется, чтобы можно было получить базовую форму. Итак, нормализованная форма антинационализма — это национальных.
Нормализация полезна для уменьшения количества уникальных токенов, присутствующих в тексте, удаления вариаций слова в тексте, а также удаления избыточной информации. Популярные методы, которые используются для нормализации, — это стемминг и лемматизация.
Давайте обсудим их подробнее!
3.1 Что такое стемминг?
Stemming — это основанный на элементарных правилах процесс удаления флективных форм из токена, а выходными данными являются основы мира.
Например, «смеется», «смеется», «смеется», «смеется» превращается в «смех», что является их основой, потому что их форма перегиба будет удалена.
Создание корней не является хорошим процессом нормализации, потому что иногда при выделении корней могут образовываться слова, которых нет в словаре.Например, рассмотрим предложение: «Его команды не выигрывают»
После блокировки жетонов, которые мы получим: «привет», «команда», «есть», «не», «победа»
Обратите внимание, что ключевое слово «winn» не является обычным словом, а « hi » изменило контекст всего предложения.
Другой пример —
3.2 Что такое лемматизация?
Лемматизация, с другой стороны, представляет собой систематический пошаговый процесс удаления форм словоизменения.Он использует словарный запас, структуру слов, часть речевых тегов и грамматические отношения.
Результатом лемматизации является корневое слово, которое называется a lemma . Например,
Am, Are, Is >> Be
Бег, Бег, Бег >> Бег
Кроме того, поскольку это систематический процесс при выполнении лемматизации, можно указать часть речевого тега для желаемого термина, и лемматизация будет выполняться только в том случае, если данное слово имеет правильную часть речевого тега.Например, если мы попытаемся лемматизировать слово , выполняющее , как глагол , оно будет преобразовано в run. Но если мы попытаемся лемматизировать то же слово , идущее с , как существительное , оно не будет преобразовано.
Подробное объяснение того, как работает лемматизация, с помощью пошагового процесса удаления форм словоизменения —
Давайте теперь посмотрим на некоторые свойства текстовых объектов, связанные с синтаксисом и структурой. Речь пойдет о части речевых тегов и грамматики.
4. Часть тегов речи (PoS) при обработке естественного языка —
Часть речевых тегов или тегов PoS — это свойства слов, которые определяют их основной контекст, их функцию и использование в предложении. Некоторые из наиболее часто используемых частей речевых тегов: Существительные , которые определяют любой объект или сущность; Глаголы , которые определяют действие; и Прилагательные или Наречия , которые действуют как модификаторы, квантификаторы или усилители в любом предложении.В предложении каждое слово будет связано с соответствующей частью речевого тега, например,
.«Дэвид купил новый ноутбук в магазине Apple».
В нижеследующем предложении каждое слово связано с частью речевого тега, который определяет их функции.
В данном случае «Дэвид» имеет тег NNP , что означает, что это существительное собственное, «имеет» и «куплен» принадлежит глаголу, указывающему на то, что это действия, а «ноутбук» и «магазин Apple» — существительные, « новый »- это прилагательное, роль которого заключается в изменении контекста ноутбука.
Часть речевых тегов определяется отношениями слов к другим словам в предложении. Модели машинного обучения или модели на основе правил применяются для получения части речевых тегов слова. Наиболее часто используемая часть обозначений речевых тегов обеспечивается Penn Part of Speech Tagging.
Часть речевых тегов имеет большое количество приложений, и они используются в различных задачах, таких как очистка текста , задачи разработки функций и устранение неоднозначности .Например, рассмотрим эти два предложения —
Предложение 1: «Пожалуйста, , забронируйте мой рейс в Нью-Йорк»
Предложение 2: «Я люблю читать книгу в Нью-Йорке»
В обоих предложениях используется ключевое слово «книга», но в первом предложении оно используется как глагол, а во втором предложении — как существительное.
5. Грамматика в НЛП и ее виды —
А теперь поговорим о грамматике. Грамматика относится к правилам формирования хорошо структурированных предложений.Первый тип грамматики — это грамматика округа .
5.1 Что такое грамматика избирательного округа?
Любое слово, группа слов или словосочетаний может быть определена как Составные части, и цель грамматики избирательного округа состоит в том, чтобы организовать любое предложение на его составные части, используя их свойства. Эти свойства обычно определяются их частью речевых тегов, идентификацией существительных или глагольных фраз.
Например, грамматика избирательного округа может определять, что любое предложение может быть организовано в три составляющие — субъект, контекст и объект.
Эти составляющие могут принимать разные значения и, соответственно, могут генерировать разные предложения. Например, у нас есть следующие составляющие —
Вот некоторые из примеров предложений, которые могут быть созданы с использованием этих составляющих: —
«В парке лают собаки».
«Они с удовольствием едят».
«Кошки бегают с утра».
Еще один способ взглянуть на грамматику округа — определить их грамматику в терминах их части речевых тегов.Назовите грамматическую структуру, содержащую [определитель, существительное] [прилагательное, глагол] [предлог, определитель, существительное], которое соответствует тому же предложению — «Собаки лают в парке».
5.2 Что такое грамматика зависимостей?
Другой тип грамматики — это грамматика зависимостей, которая утверждает, что слова предложения зависят от других слов предложения. Например, в предыдущем предложении было упомянуто «лай собаки», и собака была изменена лаем, поскольку между ними существует модификатор прилагательного зависимости.
Грамматика зависимостей упорядочивает слова предложения в соответствии с их зависимостями. Одно из слов в предложении действует как корень, а все остальные слова прямо или косвенно связаны с корнем, используя свои зависимости. Эти зависимости представляют отношения между словами в предложении, а грамматики зависимостей используются для вывода структурных и семантических зависимостей между словами.
Рассмотрим пример. Рассмотрим предложение:
«Analytics Vidhya — крупнейшее сообщество специалистов по данным, предоставляющее лучшие ресурсы для понимания данных и аналитики.”
Дерево зависимостей этого предложения выглядит примерно так —
В этом дереве корневым словом является « community », имеющее NN как часть речевого тега, и каждое второе слово этого дерева связано с корнем, прямо или косвенно, с отношением зависимости, таким как прямой объект, прямая тема, модификаторы и др.
Эти отношения определяют их роли и функции каждого слова в предложении, а также то, как несколько слов связаны друг с другом.Каждая зависимость может быть представлена в виде триплета, который содержит регулятор, отношение и зависимый,
, что означает, что иждивенец связан с управляющим отношением, или, другими словами, они являются субъектом, глаголом и объектом соответственно. Например, в том же предложении: «Analytics Vidhya — крупнейшее сообщество специалистов по данным»
«Analytics Vidhya» — это субъект и играет роль регулятора , глагол здесь «есть» и играет роль отношения , и «крупнейшего сообщества специалистов по данным» это зависимый или объект .
Грамматики зависимостей могут использоваться в разных сценариях использования —
- Распознавание именованных объектов — они используются для решения задач распознавания именованных объектов.
- Вопросно-ответная система — их можно использовать для понимания реляционных и структурных аспектов вопросно-ответных систем.
- Разрешение Coreference — они также используются в разрешениях Coreference, в которых задача состоит в том, чтобы сопоставить местоимения с соответствующими словосочетаниями.
- Резюмирование текста и классификация текста — их также можно использовать для задач реферирования текста, и они также используются как функции для задач классификации текста.
Конечные ноты
В этой статье мы рассмотрели основы обработки естественного языка.
Роль НЛП в современном мире стремительно растет. При таком объеме производимых неструктурированных данных эффективно только овладеть этим навыком или, по крайней мере, понять его до такого уровня, чтобы вы, как специалист по данным, могли понять его.
Если вас интересует полноценный курс по обработке естественного языка, охватывающий все, от базового до экстремального, то здесь программа Analytics Vidhya’s Certified Natural Language Processing Master Program
Дайте нам знать в комментариях ниже, если у вас есть какие-либо сомнения относительно этой статьи.
Связанные
Введение в обработку текста на естественном языке | Автор: Венцислав Йорданов
Прочитав этот пост в блоге, вы узнаете некоторые основные методы извлечения функций из , некоторого текста , так что вы можете использовать эти функции в качестве входных для моделей машинного обучения .
NLP — это подраздел компьютерных наук и искусственного интеллекта, связанный с взаимодействием между компьютерами и человеческими (естественными) языками. Он используется для применения алгоритмов машинного обучения к тексту и речи .
Например, мы можем использовать NLP для создания таких систем, как распознавание речи , обобщение документов , машинный перевод , обнаружение спама , распознавание именованных сущностей , ответы на вопросы , автозаполнение, предиктивный ввод и т. Д. на.
В настоящее время у большинства из нас есть смартфоны с функцией распознавания речи. Эти смартфоны используют НЛП, чтобы понимать, что говорится. Также многие люди используют ноутбуки, операционная система которых имеет встроенное распознавание речи.
Некоторые примеры
Cortana
Источник: https://blogs.technet.microsoft.com/microsoft_presse/auf-diesen-4-saeulen-basiert-cortanas-persoenlichkeit/В ОС Microsoft есть виртуальный помощник под названием Cortana , которая может распознавать естественный голос .Вы можете использовать его, чтобы настраивать напоминания, открывать приложения, отправлять электронные письма, играть в игры, отслеживать рейсы и посылки, проверять погоду и т. Д.
Подробнее о командах Кортаны можно прочитать здесь.
Siri
Источник: https://www.analyticsindiamag.com/behind-hello-siri-how-apples-ai-powered-personal-assistant-uses-dnn/Siri — виртуальный помощник Apple Inc. операционные системы iOS, watchOS, macOS, HomePod и tvOS. Опять же, вы можете делать много вещей с голосом командами : начать звонок, написать кому-нибудь, отправить электронное письмо, установить таймер, сделать снимок, открыть приложение, установить будильник, использовать навигацию и так далее.
Вот полный список всех команд Siri.
Gmail
Источник: https://i.gifer.com/Ou1t.gifЗнаменитый почтовый сервис Gmail , разработанный Google, использует обнаружения спама для фильтрации некоторых спам-писем.
NLTK ( Natural Language Toolkit ) — это ведущая платформа для создания программ Python для работы с данными на человеческом языке . Он предоставляет простые в использовании интерфейсы для многих корпусов и лексических ресурсов .Кроме того, он содержит набор из библиотек обработки текста для классификации, токенизации, выделения корней, тегов, синтаксического анализа и семантического обоснования. Лучше всего то, что NLTK — это бесплатный проект с открытым исходным кодом, управляемый сообществом.
Мы воспользуемся этим набором инструментов, чтобы показать некоторые основы обработки естественного языка. В приведенных ниже примерах я предполагаю, что мы импортировали инструментарий NLTK. Мы можем сделать это так: import nltk .
В этой статье мы рассмотрим следующие темы:
- Токенизация предложений
- Токенизация слов
- Лемматизация текста и выделение стемми
- Стоп-слова
- Регулярное выражение
- Пакет слов
- TF-IDF
1.Токенизация предложения
Токенизация предложения (также называемая сегментацией предложения ) — это проблема деления строки письменного языка на его компонент предложения . Идея здесь выглядит очень простой. На английском и некоторых других языках мы можем разделить предложения, когда увидим знак препинания.
Однако даже в английском языке эта проблема нетривиальна из-за использования символа полной остановки для сокращений. При обработке обычного текста таблицы сокращений, содержащие точки, могут помочь нам предотвратить неправильное присвоение границ предложения .Во многих случаях мы используем библиотеки, чтобы сделать эту работу за нас, поэтому пока не особо беспокойтесь о деталях.
Пример :
Давайте посмотрим отрывок текста об известной настольной игре под названием нарды.
Нарды — одна из старейших известных настольных игр. Его историю можно проследить почти 5000 лет назад до археологических открытий на Ближнем Востоке. Это игра для двух игроков, в которой каждый игрок имеет пятнадцать шашек, которые перемещаются между двадцатью четырьмя точками в соответствии с броском двух кубиков.
Чтобы применить токенизацию предложения с помощью NLTK, мы можем использовать функцию nltk.sent_tokenize .
В качестве вывода мы получаем 3 составных предложения по отдельности.
Нарды - одна из старейших известных настольных игр.Его история насчитывает почти 5000 лет, начиная с археологических открытий на Ближнем Востоке.
Это игра для двух игроков, в которой каждый игрок имеет пятнадцать шашек, которые перемещаются между двадцатью четырьмя точками в соответствии с броском двух кубиков.
2. Разметка слов
Разметка слов (также называемая сегментацией слов ) — это проблема деления строки письменного языка на , составляющую слова . В английском и многих других языках, в которых используется латинский алфавит, пробел является хорошим приближением к разделителю слов.
Тем не менее, у нас все еще могут быть проблемы, если мы будем разделять только по пробелам для достижения желаемых результатов. Некоторые составные существительные в английском языке пишутся по-разному и иногда содержат пробел.В большинстве случаев мы используем библиотеку для достижения желаемых результатов, поэтому снова не беспокойтесь о деталях.
Пример :
Давайте воспользуемся предложениями из предыдущего шага и посмотрим, как мы можем применить к ним токенизацию слов. Мы можем использовать функцию nltk.word_tokenize .
Вывод:
['Нарды', 'есть', 'один', 'из', 'самый старый', 'известный', 'доска', 'игры', '.'][' Его ',' история ',' может ',' быть ',' прослеживаться ',' назад ',' почти ',' 5000 ',' лет ',' до ',' археологические ',' открытия ',' в ' , 'Ближний Восток', '.']
[' Это ',' есть ',' a ',' два ',' игрок ',' игра ',' где ',' каждый ',' игрок ',' имеет ',' пятнадцать ',' шашки ',' которые ',' двигаться ',' между ',' двадцать четыре ',' очки ',' согласно ',' до ',' the ',' roll ',' of ',' two ',' dice ','. ']
Лемматизация текста и стемминг
По грамматическим причинам документы могут содержать различных форм слова , например, , , , , , . Кроме того, иногда у нас есть связанных слова с аналогичным значением, например, нация , национальность , национальность .
Цель как , так и лемматизации состоит в том, чтобы сократить флективную флективную форму и иногда производные формы слова до общей базовой формы .
Источник: https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
Примеры :
- am, are, is
=>быть - собака, собаки, собаки, собаки
=>собака
Результат этого сопоставления, примененного к тексту, будет примерно таким:
- собаки мальчика разных размеров
=>собака быть разным размером
Стемминг и лемматизация являются частными случаями нормализации .Однако они отличаются друг от друга.
Основание обычно относится к грубому эвристическому процессу процессу , который обрезает концы слов в надежде на правильное достижение этой цели большую часть времени и часто включает удаление деривационных аффиксов.
Лемматизация обычно относится к , делающим что-то правильно с использованием словаря и морфологического анализа слов, обычно нацеленных на удаление только флективных окончаний и возвращение базовой или словарной формы слова, то есть известная как лемма .
Источник: https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
Разница в том, что стеммер работает с без знания контекста , и поэтому не может понять разницу между словами, которые имеют разное значение в зависимости от части речи. Но у стеммеров есть и некоторые преимущества: их проще реализовать, и обычно работают быстрее . Кроме того, пониженная «точность» может не иметь значения для некоторых приложений.
Примеры:
- Слово «лучше» имеет лемму «хорошо». Эта ссылка пропущена при поиске по словарю.
- Слово «игра» является базовой формой слова «игра», и, следовательно, оно совпадает как с основанием, так и с лемматизацией.
- Слово «встреча» может быть как основной формой существительного, так и формой глагола («встречаться») в зависимости от контекста; например, «на нашей последней встрече» или «Мы снова встречаемся завтра». В отличие от стемминга, лемматизация пытается выбрать правильную лемму в зависимости от контекста.
После того, как мы узнаем, в чем разница, давайте рассмотрим несколько примеров с использованием инструмента NLTK.
Вывод:
Стеммер: видел
Лемматизатор: см.Стеммер: водил
Лемматизатор: привод
Стоп-слова
Источник: http://www.nepalinlp.com/detail/stop-words-removal_nepali/Стоп-слова это слова, которые отфильтрованы до или после обработки текста. При применении машинного обучения к тексту эти слова могут добавить шума .Вот почему мы хотим удалить эти нерелевантных слова .
Стоп-слова обычно относятся к наиболее распространенным словам , таким как « и », « — », « a » в языке, но не существует единого универсального списка стоп-слов. Список стоп-слов может меняться в зависимости от вашего приложения.
Инструмент NLTK имеет заранее определенный список стоп-слов, которые относятся к наиболее распространенным словам. Если вы используете его впервые, вам необходимо загрузить стоп-слова, используя этот код: nltk.скачать («стоп-слова») . После завершения загрузки мы можем загрузить пакет стоп-слов из nltk.corpus и использовать его для загрузки стоп-слов.
Вывод:
['я', 'я', 'мой', 'я', 'мы', 'наш', 'наш', 'мы', 'ты', "ты", " вы "," вы "," вы бы ", 'ваш', 'ваш', 'себя', 'себя', 'он', 'его', 'его', 'сам', ' she ', «она», «ее», «ее», «она», «это», «это», «ее», «сама», «они», «они», «их», «их» , 'себя', 'что', 'which', 'who', 'who', 'this', 'that', 'that will', 'this', 'те', 'am', 'is' , 'есть', 'был', 'были', 'быть', 'был', 'быть', 'иметь', 'иметь', 'иметь', 'иметь', 'делать', 'делает', ' сделали , 'of', 'at', 'by', 'for', 'with', 'about', 'Again', 'between', 'into', 'through', 'во время', 'до', ' после ',' выше ',' ниже ',' в ',' от ',' вверх ',' вниз ',' внутрь ',' вне ',' вкл ',' выкл ',' над ',' под ' , 'снова', 'далее', 'затем', 'один раз', 'здесь', 'там', 'когда', 'где', 'почему', 'как', 'все', 'любое', ' оба ',' каждый ',' несколько ',' больше ',' большинство ',' другие ',' некоторые ',' такие ',' нет ',' ни ',' не ',' только y ',' own ',' same ',' so ',' than ',' too ',' very ',' s ',' t ',' can ',' will ',' просто ',' не ' , «не», «должен», «должен был», «сейчас», «d», «ll», «m», «o», «re», «ve», «y», « ain ',' aren ', "not",' couldn ', "could",' didn ', "didn", "not",' doesn ', "not",' hadn ', "hadn" t ", 'hasn'," hasn't ", 'haven'," Have ", 'isn'," not ", 'ma', 'mightn'," could not ", 'mustn' , «нельзя», «не нужно», «не нужно», «шань», «не нужно», «не следует», «не следует», «не было», «не было», «не было» , «не было», «выиграл», «не буду», «не стал бы», «не стал бы»]
Давайте посмотрим, как мы можем удалить стоп-слова из предложения.
Вывод:
['Нарды', 'один', 'самый старый', 'известный', 'доска', 'игры', '.']
Если вы не знакомы с пониманием списка в Python. Вот еще один способ добиться того же результата.
Однако имейте в виду, что понимания списка на быстрее , потому что они оптимизированы для интерпретатора Python, чтобы определить предсказуемую закономерность во время цикла.
Вы можете спросить, почему мы конвертируем наш список в набор .Set — это абстрактный тип данных, который может хранить уникальные значения без какого-либо определенного порядка. Операция поиска в наборе намного быстрее , чем операция поиска в списке . Для небольшого количества слов большой разницы нет, но если у вас много слов, настоятельно рекомендуется использовать заданный тип.
Если вы хотите узнать больше о времени, затрачиваемом между различными операциями для разных структур данных, вы можете взглянуть на эту замечательную шпаргалку. abc] — не соответствует соответствует a, b или c
[a - g] — соответствует символу между a & g Регулярные выражения используют символ обратной косой черты (
'\') для обозначения специальных форм или для разрешения использования специальных символов без обращения к их особому значению.Этот код противоречит использованию Python того же символа для той же цели в строковых литералах; например, чтобы соответствовать буквальной обратной косой черте, можно было бы написать'\\\\'как строку шаблона, потому что регулярное выражение должно быть\\, а каждая обратная косая черта должна быть выражена как\\внутри обычный строковый литерал Python.Решение состоит в том, чтобы использовать нотацию необработанной строки Python для шаблонов регулярных выражений; Обратные косые черты не обрабатываются каким-либо особым образом в строковом литерале с префиксом
'r'.Итак,r "\ n"— это двухсимвольная строка, содержащая'\'и'n', а"\ n"— это односимвольная строка, содержащая новую строку. Обычно шаблоны выражаются в коде Python с использованием этой нотации необработанных строк.
Источник: https://docs.python.org/3/library/re.html?highlight=regex
Мы можем использовать регулярное выражение для применения дополнительной фильтрации к нашему тексту. Например, мы можем удалить все символы, не являющиеся словами. Во многих случаях знаки препинания не нужны, и их легко удалить с помощью регулярного выражения.
В Python модуль re предоставляет операции сопоставления регулярных выражений, аналогичные тем, которые выполняются в Perl. Мы можем использовать функцию re.sub , чтобы заменить совпадения для шаблона строкой замены. Давайте посмотрим на пример, когда мы заменяем все не-слова символом пробела.
Вывод:
«Развитие сноуборда было вдохновлено скейтбордингом, снегоходом, серфингом и лыжами»
Регулярное выражение — мощный инструмент, и мы можем создавать гораздо более сложные модели.Если вы хотите узнать больше о регулярных выражениях, я могу порекомендовать вам попробовать эти 2 веб-приложения: regexr, regex101.
Мешок слов
Источник: https://www.iconfinder.com/icons/299088/bag_iconАлгоритмы машинного обучения не могут работать напрямую с необработанным текстом, нам нужно преобразовать текст в векторы чисел. Это называется извлечением признаков .
Модель набора слов — это популярная и простая методика извлечения признаков , используемая при работе с текстом.Он описывает появление каждого слова в документе.
Чтобы использовать эту модель, нам необходимо:
- Разработать словарь известных слов (также называемых токенами )
- Выбрать показатель присутствия известных слов
Любая информация о словах порядок или структура слов отбрасывается . Вот почему он называется «мешок » и « слов». Эта модель пытается понять, встречается ли в документе известное слово, но не знает, где это слово в документе.
Интуиция подсказывает, что похожих документа имеют аналогичного содержания . Кроме того, из контента мы можем кое-что узнать о значении документа.
Пример
Давайте посмотрим, что нужно сделать для создания модели набора слов. В этом примере мы воспользуемся всего четырьмя предложениями, чтобы увидеть, как работает эта модель. В реальных задачах вы будете работать с гораздо большими объемами данных.
1. Загрузите данные
Источник: https: // www.iconfinder.com/icons/315166/note_text_iconДопустим, это наши данные, и мы хотим загрузить их как массив.
Для этого мы можем просто прочитать файл и разбить его по строкам.
Вывод:
[«Мне нравится этот фильм, он забавный», «Ненавижу этот фильм», «Это было круто! Мне это нравится »,« Хороший. Мне это нравится ».]
2. Создайте словарь
Источник: https://www.iconfinder.com/icons/2109153/book_contact_dairy_google_service_iconДавайте возьмем все уникальные слова из четырех загруженных предложений, игнорируя регистр , пунктуация и односимвольные токены.Эти слова будут нашим словарным запасом (известные слова).
Мы можем использовать класс CountVectorizer из библиотеки sklearn для разработки нашего словаря. Мы увидим, как его можно использовать, после прочтения следующего шага.
3. Создайте векторы документов
Источник: https://www.iconfinder.com/icons/1574/binary_iconЗатем нам нужно оценить слова в каждом документе. Задача здесь — преобразовать каждый необработанный текст в вектор чисел. После этого мы можем использовать эти векторы в качестве входных данных для модели машинного обучения.Самый простой метод выставления оценок — отметить наличие слов цифрой 1 для присутствия и 0 для отсутствия.
Теперь давайте посмотрим, как мы можем создать модель набора слов, используя упомянутый выше класс CountVectorizer.
Вывод :
Вот наши предложения. Теперь мы можем увидеть, как работает модель «мешка слов».
Дополнительные примечания к модели мешка слов
Источник: https://www.iconfinder.com/icons/1118207/clipboard_notes_pen_pencil_iconСложность модели мешка слов решает, как разработать словарь известных слов (токенов) и как оценить наличие известных слов.
Разработка словаря
Когда размер словаря увеличивается на , векторное представление документов также увеличивается. В приведенном выше примере длина вектора документа равна количеству известных слов.
В некоторых случаях у нас может быть огромный объем данных , и в этих случаях длина вектора, представляющего документ, может составлять тысяч или миллионы элементов. Кроме того, каждый документ может содержать только несколько известных слов из словаря.
Следовательно, векторные представления будут содержать нулей . Эти векторы с большим количеством нулей называются разреженными векторами . Они требуют больше памяти и вычислительных ресурсов.
Мы можем уменьшить число известных слов при использовании модели набора слов для уменьшения требуемой памяти и вычислительных ресурсов. Мы можем использовать методы очистки текста , которые мы уже видели в этой статье, прежде чем создавать нашу модель набора слов:
- Игнорирование регистра слов
- Игнорирование знаков препинания
- Удаление стоп-слова из наших документов
- Приведение слов к их базовой форме ( Лемматизация текста и выделение корней )
- Исправление слов с ошибками
Еще один более сложный способ создания словаря — использовать сгруппированных слов .Это изменяет объем словаря и позволяет модели набора слов получить более подробную информацию о документе. Этот подход называется н-граммов .
N-грамма — это последовательность , состоящая из , числа элементов (слова, буквы, цифры, цифры и т. Д.). В контексте корпуса текста n-граммы обычно относятся к последовательности слов. Униграмма , — это одно слово, биграмма , — это последовательность из двух слов, триграмма , — это последовательность из трех слов и т. Д.Буква «n» в «n-грамме» относится к количеству сгруппированных слов. Моделируются только n-граммы, которые появляются в корпусе, а не все возможные n-граммы.
Пример
Давайте посмотрим на все биграммы для следующего предложения:
Офисное здание открыто сегодня
Все биграммы:
- офис
- офисное здание
- здание
- открыто
- открыт сегодня
Пакет биграмм более эффективен, чем подход «мешок слов».
Оценка слов
После того, как мы создали наш словарь известных слов, нам нужно оценить вхождение слов в наши данные. Мы видели один очень простой подход — бинарный подход (1 для присутствия, 0 для отсутствия).
Некоторые дополнительные методы подсчета очков:
- Подсчет . Подсчитайте, сколько раз каждое слово встречается в документе.
- Частоты . Вычислите частоту появления каждого слова в документе из всех слов в документе.
TF-IDF
Одна из проблем с частотой слов для оценки заключается в том, что наиболее часто встречающиеся слова в документе начинают получать наивысшие оценки. Эти часто встречающиеся слова могут не содержать столько « информационного прироста » для модели по сравнению с некоторыми более редкими и специфическими для предметной области словами. Один из подходов к решению этой проблемы — штрафовать слова, которые часто встречаются во всех документах. Такой подход называется TF-IDF.
TF-IDF, сокращенно от термина частота-инверсия документа частота — это статистический показатель , используемый для оценки важности слова для документа в коллекции или корпусе.
Значение оценки TF-IDF увеличивается пропорционально тому, сколько раз слово появляется в документе, но компенсируется количеством документов в корпусе, содержащих это слово.
Давайте посмотрим на формулу, используемую для расчета показателя TF-IDF для данного термина x в документе y .
Формула TF-IDF. Источник: http://filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.htmlТеперь давайте немного разделим эту формулу и посмотрим, как разные части формулы Работа.
- Term Frequency (TF) : оценка частоты встречаемости слова в текущем документе.
- Частота обратного члена (ITF) : оценка того, насколько редко слово встречается в документах.
- Наконец, мы можем использовать предыдущие формулы для вычисления балла TF-IDF для данного термина следующим образом:
Пример
В Python мы можем использовать TfidfVectorizer класс из библиотеки sklearn для вычисления оценок TF-IDF для заданных документов.Давайте использовать те же предложения, что и в примере с набором слов.
Вывод:
Я снова добавлю сюда предложения, чтобы упростить сравнение и лучше понять, как работает этот подход.
В этом сообщении в блоге вы изучите основы НЛП для текста. В частности, вы изучили следующие концепции с дополнительными деталями:
- NLP используется для применения алгоритмов машинного обучения с на текста и речи .
- NLTK ( Natural Language Toolkit ) — это ведущая платформа для создания программ Python для работы с данными на человеческом языке
- Токенизация предложений — это проблема деления строки письменного языка на ее компонент предложений
- Лемматизация слов — это проблема деления строки письменного языка на его составляющих слов
- Цель как корня , так и лемматизации состоит в том, чтобы уменьшить словоизменения образует и иногда производные формы слова до общей базовой формы .
- Стоп-слова — это слова, которые отфильтровываются до или после обработки текста. Они обычно относятся к наиболее распространенным словам в языке.
- Регулярное выражение — это последовательность символов, определяющая шаблон поиска .
- Модель набора слов — это популярная и простая методика извлечения признаков , используемая при работе с текстом. Он описывает появление каждого слова в документе.
- TF-IDF — это статистический показатель , используемый для оценки важности из слова для документа в коллекции или корпусе.
Отлично! Теперь мы знаем основы извлечения функций из текста. Затем мы можем использовать эти функции в качестве входных данных для алгоритмов машинного обучения.
Хотите увидеть все концепции , используемые в еще одном большом примере ?
— Вот и ты! Если вы читаете с мобильного, прокрутите вниз до конца и нажмите ссылку « Desktop version ».
Вот интерактивная версия этой статьи, загруженная в Deepnote (облачная платформа Jupyter Notebook). Не стесняйтесь проверить это и поиграть с примерами.
Вы также можете проверить мои предыдущие сообщения в блоге.
Если вы хотите получать уведомления, когда я публикую новый пост в блоге, вы можете подписаться на мой свежий информационный бюллетень.
Вот мой профиль в LinkedIn на случай, если вы захотите связаться со мной. Я буду счастлив быть на связи с вами.
Спасибо за прочитанное.Надеюсь, статья вам понравилась. Если вам это нравится, пожалуйста, удерживайте кнопку хлопка и поделитесь ею с друзьями. Буду рад услышать ваш отзыв. Если у вас есть вопросы, не стесняйтесь их задавать. 😉
Что это и как работает?
Обработка естественного языка (NLP) позволяет машинам разбирать и интерпретировать человеческий язык. Он лежит в основе инструментов, которые мы используем каждый день — от программного обеспечения для перевода, чат-ботов, спам-фильтров и поисковых систем до программного обеспечения для исправления грамматики, голосовых помощников и инструментов для мониторинга социальных сетей.
Начните свое путешествие по НЛП с инструментами без кода
В этом руководстве вы узнаете об основах обработки естественного языка и некоторых ее проблемах, а также познакомитесь с наиболее популярными приложениями НЛП в бизнесе. Наконец, вы сами убедитесь, насколько легко начать работу с инструментами обработки естественного языка без кода.
- Что такое обработка естественного языка (NLP)?
- Как работает обработка естественного языка?
- Проблемы обработки естественного языка
- Примеры обработки естественного языка
- Обработка естественного языка с помощью Python
- Учебник по обработке естественного языка (NLP)
Что такое обработка естественного языка (NLP)?
Обработка естественного языка (NLP) — это область искусственного интеллекта (AI), которая делает человеческий язык понятным для машин.НЛП сочетает в себе возможности лингвистики и информатики для изучения правил и структуры языка и создания интеллектуальных систем (работающих на алгоритмах машинного обучения и НЛП), способных понимать, анализировать и извлекать значение из текста и речи.
Возьмем, к примеру, Gmail. Электронные письма автоматически классифицируются как Promotions , Social , Primary или Spam , благодаря задаче NLP, называемой извлечением ключевых слов. «Читая» слова в строке темы и связывая их с заранее заданными тегами, машины автоматически узнают, какую категорию присваивать электронным письмам.
Преимущества NLP
Есть много преимуществ NLP, но вот лишь несколько преимуществ высшего уровня, которые помогут вашему бизнесу стать более конкурентоспособным:
- Проведите крупномасштабный анализ. Natural Language Processing помогает машинам автоматически понимать и анализировать огромные объемы неструктурированных текстовых данных, таких как комментарии в социальных сетях, заявки в службу поддержки, онлайн-обзоры, новостные отчеты и многое другое.
- Автоматизируйте процессы в реальном времени. Инструменты обработки естественного языка могут помочь машинам научиться сортировать и направлять информацию практически без вмешательства человека — быстро, эффективно, точно и круглосуточно.
- Адаптируйте инструменты НЛП к вашей отрасли. Алгоритмы обработки естественного языка могут быть адаптированы к вашим потребностям и критериям, например сложный, отраслевой язык — даже сарказм и неправильно используемые слова.
Как работает обработка естественного языка?
Используя векторизацию текста, инструменты НЛП преобразуют текст в то, что может понять машина, затем алгоритмы машинного обучения загружают обучающие данные и ожидаемые выходные данные (теги), чтобы обучить машины создавать ассоциации между конкретным входом и соответствующим ему выходом.Затем машины используют методы статистического анализа, чтобы создать свой собственный «банк знаний» и определить, какие особенности лучше всего представляют тексты, прежде чем делать прогнозы для невидимых данных (новых текстов):
В конечном итоге, чем больше данных поступает в эти алгоритмы НЛП, тем точнее модели анализа текста будут.
Анализ настроений (показан на приведенной выше диаграмме) — одна из самых популярных задач НЛП, при которой модели машинного обучения обучаются классифицировать текст по полярности мнений (положительное, отрицательное, нейтральное и все промежуточное).
Попробуйте сами провести анализ настроений, набрав текст в модели НЛП, ниже
Тестируйте с собственным текстом
Это лучший инструмент анализа настроений на свете !!! Классифицируйте текстСамым большим преимуществом моделей машинного обучения является их способность учиться самостоятельно, без необходимости определять ручные правила. Вам просто нужен набор соответствующих обучающих данных с несколькими примерами тегов, которые вы хотите анализировать. А с помощью передовых алгоритмов глубокого обучения вы можете объединить несколько задач обработки естественного языка, таких как анализ тональности, извлечение ключевых слов, классификация тем, обнаружение намерений и т. Д., Для одновременной работы для получения детализированных результатов.
Общие задачи и методы НЛП
Многие задачи обработки естественного языка включают синтаксический и семантический анализ, используемый для разбиения человеческого языка на машиночитаемые фрагменты.
Синтаксический анализ , также известный как синтаксический анализ или синтаксический анализ, определяет синтаксическую структуру текста и отношения зависимости между словами, представленные на диаграмме, называемой деревом синтаксического анализа.
Семантический анализ фокусируется на определении значения языка.Однако, поскольку язык многозначен и неоднозначен, семантика считается одной из самых сложных областей в НЛП.
Семантические задачи анализируют структуру предложений, взаимодействия слов и связанных понятий, пытаясь раскрыть значение слов, а также понять тему текста.
Ниже мы перечислили некоторые из основных подзадач семантического и синтаксического анализа:
Токенизация
Токенизация — важная задача в обработке естественного языка, используемая для разделения строки слов на семантически полезные единицы, называемые жетоны .
Токенизация предложений разбивает предложения в тексте, а токенизация слов разбивает слова в предложении. Как правило, токены слов разделяются пробелами, а токены предложений — остановками. Однако вы можете выполнить токенизацию высокого уровня для более сложных структур, таких как слова, которые часто идут вместе, иначе известные как словосочетания (например, New York ).
Пример того, как токенизация слов упрощает текст:
Вот пример того, как токенизация слов упрощает текст:
Служба поддержки клиентов не может быть лучше! = «Обслуживание клиентов» «не могло» «быть» «лучше».
Тегирование части речи
Тегирование части речи (сокращенно тегирование PoS) включает добавление части категории речи к каждому токену в тексте. Некоторые общие теги PoS: глагол , прилагательное , существительное , местоимение , союз , предлог , пересечение и другие. В этом случае приведенный выше пример будет выглядеть так:
«Служба поддержки клиентов»: СУЩЕСТВИТЕЛЬНОЕ, «мог бы»: ГЛАГОЛ, «не»: НАРЕЧЕСТВО, быть »: ГЛАГОЛ,« лучше »: ПРИЛАГАЕМЫЙ,«! »: ПУНКТУАЦИЯ.
PoS-теги полезны для определения отношений между словами и, следовательно, понимания смысла предложений.
Анализ зависимостей
Грамматика зависимостей определяет способ соединения слов в предложении. Таким образом, анализатор зависимостей анализирует, как «заголовочные слова» связаны и модифицируются другими словами, а также понимает синтаксическую структуру предложения:
Анализ констант
Анализ констант направлен на визуализацию всей синтаксической структуры предложения путем определения структуры фразы грамматика. Он состоит из использования абстрактных терминальных и нетерминальных узлов, связанных со словами, как показано в этом примере:
Вы можете попробовать разные алгоритмы и стратегии синтаксического анализа в зависимости от характера текста, который вы собираетесь анализировать, и уровня сложности, который вы ‘ хочу добиться.
Лемматизация и стемминг
Когда мы говорим или пишем, мы склонны использовать изменяемые формы слова (слова в их различных грамматических формах). Чтобы сделать эти слова более понятными для компьютеров, НЛП использует лемматизацию и корчевание, чтобы преобразовать их обратно в их корневую форму.
Слово в том виде, в каком оно встречается в словаре — его корневая форма — называется леммой. Например, термины «есть, есть, есть, был и был», сгруппированы по лемме «быть». Итак, если мы применим эту лемматизацию к «У африканских слонов четыре гвоздя на передних лапах. , » результат будет выглядеть примерно так:
У африканских слонов четыре гвоздя на передних лапах =« африканец »,« слон »,« иметь »,« 4 »,« гвоздь »,« на »,« их, ”“ Foot ”]
Этот пример полезен, чтобы увидеть, как лемматизация изменяет предложение, используя его базовую форму (например,g., слово «foot» было изменено на «foot»).
Когда мы говорим о корнеобразовании, корневая форма слова называется основой.
Например, объединение слов «консультироваться», «консультант», «консультирование» и «консультанты» привело бы к коренной форме «консультировать».
В то время как лемматизация основана на словаре и выбирает подходящую лемму на основе контекста, выделение корней работает с отдельными словами без учета контекста.Например, в предложении:
«Это лучше»
Слово «лучше» преобразовано лемматизатором в слово «хорошо», но не изменилось путем выделения корней. Несмотря на то, что стеммеры могут давать менее точные результаты, их легче построить и работать быстрее, чем лемматизаторы. Но лемматизаторы рекомендуются, если вы ищете более точные лингвистические правила.
Удаление стоп-слов
Удаление стоп-слов — важный шаг в обработке текста НЛП. Он включает в себя фильтрацию часто встречающихся слов, которые добавляют небольшую семантическую ценность к предложению или не добавляют вообще ничего, например, , которое, to, at, for, is, и т. Д.
Вы даже можете настроить списки игнорируемых слов, чтобы включить в них слова, которые вы хотите игнорировать.
Допустим, вы хотите классифицировать заявки в службу поддержки клиентов по их тематике. В этом примере: «Здравствуйте, у меня проблемы с входом в систему с новым паролем» , может быть полезно удалить стоп-слова, такие как «привет» , «I» , «am» , «С» , «мой» , поэтому у вас останутся слова, которые помогут вам понять тему билета: «проблема» , «вход в систему» , «новый» , « пароль ».
Устранение неоднозначности смысла слов
В зависимости от контекста слова могут иметь разное значение. Возьмите слово «книга» , например:
- Вы должны прочитать эту книгу ; это отличный роман!
- Вы должны забронировать рейс как можно скорее.
- К концу года следует закрыть книги .
- Вы должны делать все по книге , чтобы избежать возможных осложнений.
Существует два основных метода, которые могут использоваться для устранения неоднозначности смысла слов (WSD): основанный на знаниях (или словарный подход) или контролируемый подход . Первый пытается вывести значение, наблюдая за словарными определениями неоднозначных терминов в тексте, а второй основан на алгоритмах обработки естественного языка, которые учатся на обучающих данных.
Распознавание именованных сущностей (NER)
Распознавание именованных сущностей — одна из самых популярных задач семантического анализа, которая включает извлечение сущностей из текста.Сущностями могут быть имена, места, организации, адреса электронной почты и т. Д.
Извлечение отношений, еще одна подзадача НЛП, идет еще дальше и находит отношения между двумя существительными. Например, во фразе «Сьюзен живет в Лос-Анджелесе» человек (Сьюзан) связан с местом (Лос-Анджелес) семантической категорией «живет в».
Классификация текста
Классификация текста — это процесс понимания значения неструктурированного текста и его организации в предварительно определенные категории (теги).Одной из самых популярных задач классификации текстов является анализ тональности, который направлен на категоризацию неструктурированных данных по тональности.
Другие задачи классификации включают обнаружение намерения, моделирование темы и определение языка.
Проблемы обработки естественного языка
Есть много проблем при обработке естественного языка, но одна из основных причин сложности НЛП заключается просто в том, что человеческий язык неоднозначен.
Даже людям сложно правильно анализировать и классифицировать человеческий язык.
Возьмем, к примеру, сарказм. Как научить машину понимать выражение, которое выражает противоположное истине? Хотя люди легко обнаружат сарказм в этом комментарии, ниже было бы сложно научить машину интерпретировать эту фразу:
«Если бы у меня был доллар за каждую умную вещь, которую вы говорите, я был бы беден».
Чтобы полностью понимать человеческий язык, специалистам по обработке данных необходимо научить инструменты НЛП выходить за рамки определений и порядка слов, понимать контекст, двусмысленность слов и другие сложные концепции, связанные с сообщениями.Но им также необходимо учитывать другие аспекты, такие как культура, происхождение и пол, при тонкой настройке моделей обработки естественного языка. Например, сарказм и юмор могут сильно отличаться от страны к стране.
Обработка естественного языка и мощные алгоритмы машинного обучения (часто несколько используемых в совместной работе) улучшаются и упорядочивают хаос человеческого языка, вплоть до таких понятий, как сарказм. Мы также начинаем видеть новые тенденции в НЛП, поэтому мы можем ожидать, что НЛП произведет революцию в способах сотрудничества людей и технологий в ближайшем будущем и за его пределами.
Примеры обработки естественного языка
Хотя обработка естественного языка продолжает развиваться, уже существует множество способов ее использования сегодня. Большую часть времени вы будете подвергаться обработке естественного языка, даже не осознавая этого.
Часто НЛП работает в фоновом режиме с инструментами и приложениями, которые мы используем каждый день, помогая предприятиям улучшить наш опыт. Ниже мы выделили некоторые из наиболее распространенных и наиболее эффективных применений обработки естественного языка в повседневной жизни:
11 Типичных примеров НЛП
Фильтры электронной почты
Как упоминалось выше, фильтры электронной почты являются одними из самых распространенных и наиболее распространенных. основные виды использования НЛП.Когда они были впервые представлены, они не были полностью точными, но, учитывая годы обучения машинному обучению на миллионах выборок данных, в наши дни электронные письма редко попадают не в тот почтовый ящик.
Виртуальные помощники, голосовые помощники или интеллектуальные динамики
Наиболее распространенными являются Siri от Apple и Alexa от Amazon. Виртуальные помощники используют технологию машинного обучения NLP для понимания и автоматической обработки голосовых запросов. Алгоритмы обработки естественного языка позволяют отдельным пользователям настраивать помощников без дополнительных вводных данных, учиться на предыдущих взаимодействиях, вспоминать связанные запросы и подключаться к другим приложениям.
Ожидается, что использование голосовых помощников будет продолжать расти в геометрической прогрессии, поскольку они используются для управления домашними системами безопасности, термостатами, освещением и автомобилями — даже если вы знаете, что у вас заканчивается в холодильнике.
Интернет-поисковые системы
Когда вы выполняете простой поиск в Google, вы используете машинное обучение НЛП. Они используют хорошо обученные алгоритмы, которые не только ищут связанные слова, но и определяют намерения пользователя. Результаты часто меняются ежедневно, следуя трендовым запросам и трансформируясь вместе с человеческим языком.Они даже учатся предлагать темы и темы, связанные с вашим запросом, о которых вы, возможно, даже не подозревали, что вас интересовали.
Предиктивный текст
Каждый раз, когда вы набираете текст на своем смартфоне, вы видите НЛП в действии. Часто вам нужно ввести всего несколько букв в слове, и приложение для текстовых сообщений предложит вам правильную букву. И чем больше вы набираете текст, тем точнее он становится. Часто часто используемые слова и имена распознаются быстрее, чем вы можете их вводить.
Интеллектуальный ввод текста, автозамена и автозаполнение стали настолько точными в программах обработки текстов, как MS Word и Google Docs, что они могут заставить нас почувствовать, что нам нужно вернуться в гимназию.
Отслеживание настроений бренда в социальных сетях
Анализ настроений — это автоматизированный процесс классификации мнений в тексте на положительные, отрицательные или нейтральные. Его часто используют для отслеживания настроений в социальных сетях. Вы можете отслеживать и анализировать настроения в комментариях к вашему бренду, продукту, конкретной функции или сравнивать свой бренд с конкурентами.
Представьте, что вы только что выпустили новый продукт и хотите определить первоначальную реакцию своих клиентов. Возможно, клиент написал в Твиттере недовольство вашим обслуживанием.Отслеживая анализ настроений, вы можете сразу заметить эти негативные комментарии и немедленно ответить.
Быстрая сортировка отзывов клиентов
Классификация текста — это основная задача НЛП, которая назначает предварительно определенные категории (теги) тексту на основе его содержимого. Он отлично подходит для организации качественной обратной связи (обзоры продуктов, обсуждения в социальных сетях, опросы и т. Д.) По соответствующим темам или категориям отделов.
Retently, платформа SaaS, использовала инструменты NLP, чтобы классифицировать ответы NPS и практически мгновенно получить полезную информацию:
Сдержанно обнаружил наиболее актуальные темы, упомянутые клиентами, и те, которые они ценили больше всего.Ниже вы можете видеть, что в большинстве ответов упоминались «Характеристики продукта», за которыми следовали «UX продукта» и «Поддержка клиентов» (последние две темы были упомянуты в основном промоутерами).
Автоматизация процессов обслуживания клиентов
Другие интересные приложения НЛП связаны с автоматизацией обслуживания клиентов. Эта концепция использует технологию на основе искусственного интеллекта для устранения или сокращения рутинных ручных задач в поддержке клиентов, экономии драгоценного времени агентов и повышения эффективности процессов.
Согласно тесту Zendesk, техническая компания получает +2600 запросов в службу поддержки в месяц. Получение большого количества заявок в службу поддержки по разным каналам (электронная почта, социальные сети, чат и т. Д.) Означает, что компаниям необходимо разработать стратегию для классификации каждого входящего запроса.
Текстовая классификация позволяет компаниям автоматически помечать входящие обращения в службу поддержки клиентов в соответствии с их темой, языком, настроениями или срочностью. Затем, на основе этих тегов, они могут мгновенно направлять билеты наиболее подходящему пулу агентов.
Uber разработал собственный рабочий процесс маршрутизации билетов, который включает в себя тегирование билетов по стране, языку и типу (эта категория включает вложенные теги Driver-Partner, Вопросы о платежах, утерянных предметах и т. Д. ), а также следующие правила приоритизации, такие как отправка запросов от новых клиентов ( New Driver-Partners ), отправляются в начало списка.
Чат-боты
Чат-бот — это компьютерная программа, имитирующая человеческий разговор.Чат-боты используют НЛП, чтобы распознать смысл предложения, определить соответствующие темы и ключевые слова, даже эмоции, и предложить лучший ответ на основе их интерпретации данных.
Поскольку клиенты жаждут быстрой, персонализированной и круглосуточной поддержки, чат-боты стали героями стратегий обслуживания клиентов. Чат-боты сокращают время ожидания клиентов, обеспечивая немедленные ответы, и особенно хорошо справляются с обычными запросами (которые обычно представляют собой наибольший объем запросов в службу поддержки), позволяя агентам сосредоточиться на решении более сложных проблем.Фактически, чат-боты могут решить до 80% обычных обращений в службу поддержки.
Помимо поддержки клиентов, чат-ботов можно использовать для рекомендации продуктов, предложения скидок и бронирования, а также для многих других задач. Для этого большинство чат-ботов следуют простой логике «если / то» (они запрограммированы так, чтобы определять намерения и связывать их с определенным действием) или предоставляют выбор вариантов на выбор.
Автоматическое суммирование
Автоматическое суммирование состоит из уменьшения текста и создания краткой новой версии, содержащей наиболее важную информацию.Это может быть особенно полезно для обобщения больших фрагментов неструктурированных данных, например научных статей.
Существует два различных способа использования НЛП для реферирования:
- Для извлечения наиболее важной информации из текста и использования ее для создания сводки (резюмирование на основе извлечения)
- Применение методов глубокого обучения для перефразирования текста и создавать предложения, которых нет в исходном источнике (резюмирование на основе абстракции) .
Автоматическое суммирование может быть особенно полезно для ввода данных, когда релевантная информация извлекается, например, из описания продукта и автоматически вводится в базу данных.
Машинный перевод
Возможность перевода текста и речи на разные языки всегда была одним из основных интересов в области НЛП. Начиная с первых попыток перевода текста с русского на английский в 1950-х годах до современных нейронных систем глубокого обучения, машинный перевод (МП) претерпел значительные улучшения, но все еще представляет собой проблемы.
Google Translate, Microsoft Translator и Facebook Translation App являются одними из ведущих платформ для универсального машинного перевода. В августе 2019 года модель машинного перевода Facebook AI с английского на немецкий заняла первое место в конкурсе, проводимом Конференцией по машинному обучению (WMT). Переводы, полученные с помощью этой модели, были определены организаторами как «сверхчеловеческие» и считались значительно превосходящими переводы, выполненные людьми-экспертами.
Еще одна интересная разработка в области машинного перевода связана с настраиваемыми системами машинного перевода, которые адаптированы к определенной области и обучены понимать терминологию, связанную с определенной областью, такой как медицина, право и финансы.Например, Lingua Custodia — это инструмент машинного перевода, предназначенный для перевода технических финансовых документов.
Наконец, одна из последних инноваций в машинном переводе — это адаптивный машинный перевод, который состоит из систем, которые могут учиться на исправлениях в режиме реального времени.
Генерация естественного языка
Генерация естественного языка (NLG) — это подполе NLP, предназначенное для создания компьютерных систем или приложений, которые могут автоматически создавать все виды текстов на естественном языке, используя семантическое представление в качестве входных данных.Некоторые из приложений NLG — это ответы на вопросы и резюмирование текста.
В 2019 году компания Open AI, занимающаяся искусственным интеллектом, выпустила GPT-2, систему генерации текста, которая стала революционным достижением в области искусственного интеллекта и вывела сферу NLG на совершенно новый уровень. Система была обучена с помощью массивного набора данных из 8 миллионов веб-страниц, и она способна генерировать последовательные и высококачественные фрагменты текста (например, новостные статьи, рассказы или стихи) при минимальном количестве запросов.
Модель работает лучше, когда в ней представлены популярные темы, которые широко представлены в данных (например, Brexit), в то время как она предлагает худшие результаты, когда запрашивается узкоспециализированный или технический контент.Тем не менее, возможности этого только начинают изучаться.
Обработка естественного языка с помощью Python
Теперь, когда вы получили некоторое представление об основах НЛП и его текущих приложениях в бизнесе, вам может быть интересно, как применить НЛП на практике.
Существует множество библиотек с открытым исходным кодом, предназначенных для работы с обработкой естественного языка. Эти библиотеки бесплатны, гибки и позволяют создавать полное и индивидуальное решение НЛП.
Однако создание всей инфраструктуры с нуля требует многолетнего опыта в области науки о данных и программирования, или вам, возможно, придется нанять целые группы инженеров.
Инструменты SaaS, с другой стороны, представляют собой готовые к использованию решения, которые позволяют вам легко и с минимальной настройкой включать NLP в инструменты, которые вы уже используете. Подключить инструменты SaaS к вашим любимым приложениям через их API-интерфейсы легко и требует всего нескольких строк кода. Это отличная альтернатива, если вы не хотите тратить время и ресурсы на изучение машинного обучения или НЛП.
Взгляните на дискуссию о строительстве и покупке, чтобы узнать больше.
Вот список лучших инструментов НЛП:
- MonkeyLearn — это платформа SaaS, которая позволяет создавать настраиваемые модели обработки естественного языка для выполнения таких задач, как анализ тональности и извлечение ключевых слов.Разработчики могут подключать модели NLP через API в Python, в то время как те, у кого нет навыков программирования, могут загружать наборы данных через интеллектуальный интерфейс или подключаться к повседневным приложениям, таким как Google Sheets, Excel, Zapier, Zendesk и т. Д.
- Набор средств естественного языка (NLTK) — это набор библиотек для создания программ Python, которые могут справляться с широким спектром задач НЛП. Это самая популярная библиотека Python для НЛП, за ней стоит очень активное сообщество, и она часто используется в образовательных целях.Есть руководство и учебник по использованию NLTK, но это довольно крутая кривая обучения.
- SpaCy — это бесплатная библиотека с открытым исходным кодом для расширенной обработки естественного языка в Python. Он был специально разработан для создания приложений НЛП, которые могут помочь вам понять большие объемы текста.
- TextBlob — это библиотека Python с простым интерфейсом для выполнения различных задач НЛП. Созданный на основе NLTK и другой библиотеки под названием Pattern, он интуитивно понятен и удобен в использовании, что делает его идеальным для начинающих.Узнайте больше о том, как использовать TextBlob и его функции.
Решения SaaS, такие как MonkeyLearn, предлагают готовые инструменты НЛП для анализа текста.
Вы можете загрузить файл CSV или Excel для крупномасштабного пакетного анализа, использовать одну из множества интеграций или подключиться через MonkeyLearn API.
Готовые модели отлично подходят для того, чтобы сделать первые шаги в анализе тональности. А когда вам нужно проанализировать отраслевые данные, вы можете создать собственный классификатор для получения более точных результатов.
Создание пользовательской модели анализа настроений
Запросите демонстрацию у MonkeyLearn, чтобы получить доступ к построителю моделей без кода. Затем выполните следующие быстрые шаги:
1. Выберите тип модели. Перейдите на панель управления, нажмите «Создать модель» и выберите «Классификатор».
2. Выберите тип классификатора. В данном случае «Анализ настроений».
3. Загрузите данные обучения. Вы можете импортировать данные из файла CSV или Excel или подключиться к любой из сторонних интеграций, предлагаемых MonkeyLearn, например Twitter, Gmail, Zendesk и т. Д.Эти данные будут использоваться для обучения вашей модели машинного обучения.
4. Пометьте свои данные. Пришло время обучить классификатор анализа настроений, вручную пометив примеры данных как положительные, отрицательные или нейтральные. Модель будет учиться на основе ваших критериев. Чем больше примеров вы отметите, тем умнее станет ваша модель. Обратите внимание, что после добавления тегов к нескольким примерам ваш классификатор начнет делать собственные прогнозы.
Ваш браузер не поддерживает теги видео.
5.Проверьте свой классификатор анализа настроений. После обучения вашей модели перейдите на вкладку «Выполнить», введите собственный текст и посмотрите, как работает ваша модель. Если вас не устраивают результаты, продолжайте тренироваться.
Ваш браузер не поддерживает теги видео.
6. Запустите вашу модель! Используйте свой классификатор настроений для анализа данных. Это можно сделать тремя способами:
- Загрузить пакет данных (например, CSV или файл Excel)
- Использовать одну из доступных интеграций
- Подключиться к MonkeyLearn API
Создать собственный экстрактор ключевых слов
С помощью экстрактора ключевых слов вы можете легко извлечь самые важные и часто используемые слова и фразы из текста, будь то набор обзоров продуктов или тысячи ответов NPS.Вы можете использовать эту предварительно обученную модель для извлечения ключевых слов или создать свой собственный экстрактор с вашими данными и критериями.
Шесть быстрых шагов для создания пользовательского экстрактора ключевых слов с помощью MonkeyLearn:
1. Выберите тип модели. Перейдите на панель управления, нажмите «Создать модель» и выберите «Экстрактор».
2. Импортируйте текстовые данные. Вы можете загрузить файл CSV или Excel.
3. Укажите данные, которые вы будете использовать для обучения экстрактора ключевых слов. Выберите, какие столбцы вы будете использовать для обучения вашей модели.
4. Определите свои теги. Создайте разные категории (теги) для типа данных, которые вы хотите получить из своего текста. В этом примере мы проанализируем набор отзывов об отелях и выделим ключевые слова, относящиеся к «аспектам» (характеристика или тема обзора) и «качеству» (ключевые слова, которые относятся к состоянию определенного аспекта).
5. Обучите свой экстрактор ключевых слов. Вам нужно будет вручную пометить примеры, выделив ключевое слово в тексте и назначив правильный тег.
Ваш браузер не поддерживает теги видео.
6. Протестируйте свою модель. Вставьте новый текст в текстовое поле, чтобы увидеть, как работает ваш экстрактор ключевых слов.
Ваш браузер не поддерживает теги видео.
7. Заставьте вашу модель работать! Загрузите данные в пакетном режиме, попробуйте одну из наших интеграций или подключитесь к MonkeyLearn API.
Заключительные слова по обработке естественного языка
Обработка естественного языка трансформирует способ анализа и взаимодействия с языковыми данными с помощью обучающих машин для понимания текста и речи и выполнения автоматических задач, таких как перевод, обобщение, классификация и извлечение .
Не так давно идея компьютеров, способных понимать человеческий язык, казалась невозможной. Однако за относительно короткое время — благодаря исследованиям и разработкам в области лингвистики, информатики и машинного обучения — НЛП стало одной из самых многообещающих и быстрорастущих областей ИИ.
По мере развития технологий НЛП становится все более доступным. Благодаря программному обеспечению на основе НЛП, такому как MonkeyLearn, компаниям становится проще создавать индивидуальные решения, которые помогают автоматизировать процессы и лучше понимать своих клиентов.
Готовы начать заниматься НЛП?
Запросите демонстрацию и сообщите нам, как мы можем помочь вам начать работу.
Нейролингвистическое программирование (НЛП) | SkillsYouNeed
Что такое нейролингвистическое программирование?
Нейролингвистическое программирование, или НЛП, предоставляет практические способы, с помощью которых вы можете изменить свой образ мышления, взгляды на прошлые события и подход к своей жизни.
Нейро-лингвистическое программирование показывает вам, как взять под контроль свой разум и, следовательно, свою жизнь.В отличие от психоанализа, который фокусируется на «, почему », НЛП очень практично и фокусируется на «, как ».
Как возникло НЛП
НЛП был создан в соавторстве с Ричардом Бэндлером, который заметил, что традиционные методы психотерапии не всегда работают, и был заинтересован в том, чтобы попробовать разные способы. Он работал в тесном сотрудничестве с очень успешным терапевтом по имени Вирджиния Сатир, и НЛП родилось из техник, которые действительно работали с пациентами и другими людьми.
Ричард Бэндлер написал много книг о НЛП.Одним из наиболее полезных в качестве базового введения, вероятно, является: Как взять на себя ответственность за свою жизнь: Руководство пользователя по NLP Ричарда Бэндлера, Алессио Роберти и Оуэна Фицпатрика.
Взять под контроль свой разум: принцип, лежащий в основе НЛП
НЛП работает с исходной точки, которую вы можете не контролировать в своей жизни, но всегда можете контролировать то, что происходит в вашей голове.
Ваши мысли, чувства и эмоции — это не вещи, которые имеют или что у вас есть , а вещи, которые вы делаете .Их причины часто могут быть очень сложными, включая, например, комментарии или убеждения ваших родителей или учителей или события, которые вы пережили.
НЛП показывает вам, как вы можете взять под контроль эти убеждения и влияния. Используя интеллектуальные техники, такие как визуализация, вы можете изменить то, как вы думаете и чувствуете прошлые события, страхи и даже фобии.
Вы не всегда можете контролировать происходящее, но всегда можете контролировать, как вы с этим справляетесь.
Ричард Бэндлер, Алессио Роберти и Оуэн Фицпатрик, Как взять на себя ответственность за свою жизнь: Руководство пользователя по НЛП
Сила веры
То, во что вы верите, может быть чрезвычайно сильным.
Если вы считаете, что заболели и собираетесь умереть, вы, вероятно, так и сделаете: ведьмы веками использовали эту технику.
Точно так же, если вы считаете, что вам дали что-то, что сделает вас лучше, вы часто поправляетесь. Этот «эффект плацебо» хорошо документирован в клинических испытаниях.
Все это сводится к тому, что если вы верите, что можете что-то сделать, то, вероятно, сможете. Но вы также можете бросить вызов ограничивающим убеждениям и изменить свое мнение о том, что можете что-то сделать, задав себе такие вопросы, как:
- Откуда мне знать, что я не могу этого сделать?
- Кто мне это сказал? Могли ли они ошибаться?
Постановка целей
Все мы знакомы с принципами постановки целей, но НЛП предлагает некоторые интересные новые идеи, сосредоточенные на удовлетворении, а не на неудовлетворенности.
Например, полезно ставить перед собой позитивные цели; сосредоточьтесь на том, что вы хотите иметь, а не на том, что вы хотели бы потерять или не иметь. Вам также следует подумать о том, чего вы действительно хотите. Например, вы на самом деле не хотите покупать дома своей мечты, вы хотите, чтобы жили в нем . Намного легче добиться цели, которая действительно вас удовлетворяет.
Сила вопросов
Бэндлер предполагает, что наш разум активно ищет ответы на вопросы.
Итак, если вы спросите себя: «, почему я так плохо себя чувствую? ’, ваш разум найдет много ответов, и вам станет хуже. В НЛП главное — задавать правильные вопросы, например:
- Почему я хочу поменять?
- Какой будет жизнь, когда я измениюсь?
- Что мне нужно делать больше / меньше, чтобы измениться?
Подобные вопросы, естественно, приводят к более позитивному восприятию.
Некоторые инструменты и методы из НЛП
В НЛП используется множество инструментов и техник, и в этом разделе дается краткое введение в некоторые из них.
Чтобы узнать больше, вы можете пройти уважаемый курс НЛП или прочитать одну из книг Ричарда Бэндлера.
Движущиеся изображения
- Представьте себе образ человека, который вас раздражает. Сосредоточьтесь на том, как картинка появляется у вас в голове.
- Уменьшите изображение, поместите его в черно-белый цвет и представьте, как оно удаляется от вас. Обратите внимание на то, как вы себя чувствуете.
- Представьте себе картину того, что заставляет вас чувствовать себя хорошо.Сделайте его больше и ярче и переместите ближе к себе. Обратите внимание на то, как вы себя чувствуете.
Идея этого мыслительного процесса заключается в том, что он помогает вам увидеть, как люди или события влияют на вас, и понять, как вы к ним относитесь.
Управляя изображениями таким образом, вы учите свой мозг усиливать хорошие чувства и ослаблять плохие.
Подрыв критического голоса
Многие из нас признают, что у нас в голове есть критический голос, который всплывает в неподходящие моменты и говорит что-то вроде « Ты не сможешь сделать это, » или « Это звучит слишком сложно для кого-то вроде тебя ». .
В следующий раз, когда вы услышите критический голос, представьте, что он звучит глупо, например, как Дональд Дак или Твити Пай.
Обратите внимание, как это меняет ваше отношение к «мудрости» голоса.
Если голос больше не похож на чей-то реальный, его гораздо легче заставить замолчать.
Запуск фильма в обратном направлении
Если у вас был плохой опыт, который вы изо всех сил пытаетесь преодолеть, может помочь вообразить его задом наперед.
- Начните с того момента времени, когда вы поняли, что опыт окончен. Затем представьте, что весь инцидент происходит в обратном направлении, пока вы не вернетесь в то время, когда это произошло.
- Сделайте это несколько раз, пока не ознакомитесь с тем, как «фильм» воспроизводится задом наперед.
- Теперь сделайте его по-настоящему маленьким в уме — скажите достаточно мало, чтобы просмотреть его на экране мобильного телефона — и воспроизведите его снова в обратном порядке.
- Наконец, подумайте о другом конце опыта, который заставит вас улыбнуться.Обратите внимание, как изменилось ваше отношение к этому.
Ключ к этой технике состоит в том, что вы показываете своему мозгу другой способ взглянуть на воспоминание, что также изменит ваше отношение к нему.
«Brilliance Squared»
- Возьмите эмоцию, которую вы хотели бы испытать, например, уверенность. Представьте цветной квадрат перед собой, залитый цветом, который у вас ассоциируется с этой эмоцией.
- Представьте себя стоящим на площади, наполненным этими эмоциями.Обратите внимание на то, как вы стоите, на выражение вашего лица, на все в вас.
- Выйдите на площадь и примите мантию воображаемого «вас». Почувствуйте, как чувство распространяется по вам. Повторите это несколько раз, пока не научитесь легко.
- А теперь представьте цветной квадрат сам по себе перед вами и войдите. Посмотрите, как он себя чувствует.
«Уловка» здесь в том, что вы тренировали свой ум ассоциировать образ с чувством.Вызывая в воображении образ, теперь вы также можете вызвать в воображении это чувство.
Заключение
НЛП — очень мощная техника, основанная на силе вашего собственного разума. Некоторые могут назвать это «уловками разума», но, используя эти техники и другие техники, разработанные практиками НЛП, вы можете научиться контролировать свой разум и то, как вы реагируете на мир.
Возможно, вы не в состоянии управлять миром, но вы можете контролировать свою реакцию на него.
Упрощенная обработка естественного языка (NLP): пошаговое руководство
Краткое введение — Что такое НЛП?
Область исследования, которая фокусируется на взаимодействии между человеческим языком и компьютером, называется обработкой естественного языка или сокращенно НЛП.Он находится на пересечении компьютерных наук, искусственного интеллекта и компьютерной лингвистики (Википедия).
НЛП — это искусственный интеллект, машинное обучение или глубокое обучение?
Ответ здесь. Сам вопрос не совсем правильный! Иногда люди неправильно используют термины AI, ML и DL. Почему бы нам сначала не упростить их, а потом вернуться.
Устранение путаницы: различия между искусственным интеллектом, машинным обучением и глубоким обучением
Начало современного ИИ можно проследить до попыток классических философов описать человеческое мышление как символическую систему.Но область ИИ не была официально основана до 1956 года, на конференции в Дартмутском колледже в Ганновере, штат Нью-Гэмпшир, где был придуман термин «искусственный интеллект».
Временная шкала о том, когда впервые появились эти жаргоны…
Теперь давайте очень кратко посмотрим, что такое искусственный интеллект, машинное обучение и глубокое обучение.
Связь AL, ML и DL можно рассматривать следующим образом.
НЛП: как НЛП вписывается в мир искусственного интеллекта?
Обладая базовыми знаниями в области искусственного интеллекта, машинного обучения и глубокого обучения, давайте вернемся к нашему самому первому запросу. НЛП — это искусственный интеллект, машинное обучение или глубокое обучение?
Слова AI, NLP и ML (машинное обучение) иногда используются почти как взаимозаменяемые.Однако в их отношениях есть порядок безумия.
Иерархически обработка естественного языка считается подмножеством машинного обучения, в то время как НЛП и машинное обучение относятся к более широкой категории искусственного интеллекта.
Natural Language Processing сочетает в себе искусственный интеллект (AI) и компьютерную лингвистику, чтобы компьютеры и люди могли беспрепятственно разговаривать.
NLP пытается преодолеть разрыв между машинами и людьми, позволяя компьютеру анализировать, что сказал пользователь (распознавание вводимой речи), и обрабатывать то, что пользователь имел в виду.Эта задача оказалась довольно сложной.
Чтобы общаться с людьми, программа должна понимать синтаксис (грамматику), семантику (значение слова), морфологию (время) и прагматику (разговор). Количество правил, которые нужно отслеживать, может показаться огромным и объясняет, почему более ранние попытки НЛП поначалу приводили к неутешительным результатам.
С другой системой, НЛП постепенно улучшалось, переходя от громоздких правил к методологии компьютерного программирования, основанной на изучении шаблонов.Siri появилась на iPhone в 2011 году. В 2012 году новое открытие использования графических процессоров (GPU) улучшило цифровые нейронные сети и NLP.
NLP позволяет компьютерным программам понимать неструктурированный контент за счет использования ИИ и машинного обучения для вывода и придания контекста языку, подобно тому, как это делает человеческий мозг. Это устройство для выявления и анализа «сигналов», содержащихся в неструктурированной информации. Тогда организации смогут глубже понять общественное мнение о своих продуктах, услугах и брендах, как и их конкуренты.
Теперь Google выпустила свой собственный движок на основе нейронной сети для восьми языковых пар, ликвидировав значительный разрыв в качестве между своей старой системой и человеком-переводчиком и способствуя растущему интересу к этой технологии. Компьютеры сегодня уже могут производить жуткое эхо человеческого языка, если их кормить соответствующим материалом.
За последние несколько лет архитектуры и алгоритмы глубокого обучения (DL) добились впечатляющих успехов в таких областях, как распознавание изображений и обработка речи.
Их применение к обработке естественного языка (NLP) сначала было менее впечатляющим, но теперь оказалось, что они вносят значительный вклад, давая самые современные результаты для некоторых распространенных задач NLP. Распознавание именованных сущностей (NER), тегирование части речи (POS) или анализ настроений — вот некоторые из проблем, при которых модели нейронных сетей превзошли традиционные подходы. Прогресс в машинном переводе, пожалуй, самый заметный из всех.
НЛП: правила игры в нашей повседневной жизни, примеры для бизнеса
НЛП — это не только создание интеллектуальных ботов…
NLP — это компьютерный инструмент для анализа, понимания и извлечения значения из естественного языка разумным и полезным способом.Это выходит далеко за рамки самых последних разработанных чат-ботов и умных виртуальных помощников. Фактически, алгоритмы обработки естественного языка используются повсюду: от поиска, онлайн-перевода, спам-фильтров и проверки орфографии.
Итак, используя NLP, разработчики могут организовывать и структурировать массу неструктурированных данных для выполнения таких задач, как интеллектуальные:
Ниже приведены некоторые из широко используемых областей НЛП.
Компоненты НЛП
НЛП можно разделить на два основных компонента.
- Понимание естественного языка
- Генерация естественного языка
Понимание естественного языка (NLU)
NLU естественно сложнее, чем задачи NLG. Действительно? Давайте посмотрим, с какими проблемами сталкивается машина, понимая ее.
При изучении языка или попытке его интерпретации возникает много двусмысленностей.
Лексическая неоднозначность может возникать, когда слово имеет другой смысл, т.е.е. имеет более одного значения, и предложение, в котором оно содержится, можно интерпретировать по-разному в зависимости от его правильного смысла. Лексическую двусмысленность можно до некоторой степени разрешить с помощью методов тегирования частей речи.
Синтаксическая неоднозначность означает, что мы видим более одного значения в последовательности слов. Это также называется грамматической двусмысленностью.
Ссылочная неоднозначность: Очень часто текст упоминается как объект (что-то / кто-то), а затем ссылается на него снова, возможно, в другом предложении, используя другое слово.Местоимение вызывает двусмысленность, когда неясно, к какому существительному относится
.Генерация естественного языка (NLG)
Это процесс создания значимых фраз и предложений в форме естественного языка из некоторого внутреннего представления.
Включает —
- Планирование текста — Включает в себя получение соответствующего контента из базы знаний.
- Планирование предложения — Включает в себя выбор необходимых слов, формирование значащих фраз, настройку тона предложения.
- Реализация текста — Отображает план предложения в структуру предложения.
Уровни НЛП
В предыдущих разделах мы обсуждали различные проблемы, связанные с НЛП. Теперь давайте посмотрим, какие все типичные шаги используются при выполнении задач НЛП. Мы должны помнить, что в следующем разделе описывается некоторый стандартный рабочий процесс, однако он может сильно отличаться, поскольку мы делаем реальные реализации на основе нашей постановки задачи или требований.
Источником естественного языка может быть речь (звук) или текст.
Фонологический анализ: Этот уровень применяется только в том случае, если источником текста является речь. Он занимается интерпретацией звуков речи внутри слов и между ними. Звук речи может дать важную подсказку о значении слова или предложения.
Это систематическое изучение организации звука. Это требует широкого обсуждения и выходит за рамки нашей текущей заметки.
Морфологический анализ: Имеет дело с пониманием отдельных слов в соответствии с их морфемами (наименьшими единицами значений).Взять, к примеру, слово: « несчастья ». Его можно разбить на три морфемы (префикс, основа и суффикс), каждая из которых передает некоторую форму значения: префикс un- относится к «небытию», а суффикс -ness относится к «состоянию бытия». Основа happy рассматривается как свободная морфема, поскольку является самостоятельным «словом». Связанные морфемы (префиксы и суффиксы) требуют свободной морфемы, к которой она может быть присоединена, и поэтому не могут появляться как «слово» сами по себе.
Лексический анализ: Включает в себя определение и анализ структуры слов. Лексика языка означает набор слов и фраз на языке. Лексический анализ делит весь текстовый текст на абзацы, предложения и слова. Я для того, чтобы заняться лексическим анализом, нам часто нужно выполнить Lexicon Normalization.
Самыми распространенными практиками нормализации лексикона являются Stemming:
- Создание основы: Создание основы — это основанный на элементарных правилах процесс удаления суффиксов («ing», «ly», «es», «s» и т. Д.) Из слова.
- Лемматизация: Лемматизация, с другой стороны, представляет собой организованную и пошаговую процедуру получения корневой формы слова, в которой используется словарный запас (словарная важность слов) и морфологический анализ (структура слова и грамматические отношения) .
Синтаксический анализ: Анализирует слова предложения, чтобы раскрыть грамматическую структуру предложения. Например … «Бесцветная зеленая идея». Это было бы отклонено анализом Symantec как бесцветное здесь; зеленый не имеет никакого смысла.
Синтаксический синтаксический анализ включает в себя анализ слов в предложении на предмет грамматики и их расположение таким образом, чтобы показать отношения между словами. Грамматика зависимостей и теги части речи являются важными атрибутами синтаксиса текста.
Семантический анализ: Определяет возможные значения предложения, сосредотачиваясь на взаимодействии между значениями уровня слова в предложении. Некоторые люди могут думать, что значение определяет уровень, но на самом деле все уровни определяют.Семантический анализатор игнорирует такие предложения, как «горячее мороженое».
Discourse Integration: Фокусируется на свойствах текста в целом, которые передают смысл, устанавливая связи между составными предложениями. Это означает ощущение контекста. Значение любого отдельного предложения, которое зависит от этого предложения. Также учитывается значение следующего предложения. Например, слово «тот» в предложении «Он хотел этого» зависит от предшествующего контекста дискурса.
Прагматический анализ: Объясняет, как дополнительный смысл читается в текстах, но не кодируется в них. Это требует обширных знаний о мире, включая понимание намерений, планов и целей. Рассмотрим следующие два предложения:
- Городская полиция отказала демонстрантам в разрешении, опасаясь насилия.
- Городская полиция отказала демонстрантам в разрешении, потому что они выступали за революцию.
Значение «они» в двух предложениях разное.Чтобы выяснить разницу, необходимо использовать мировые знания в базах знаний и модулях вывода.
Прагматический анализ помогает пользователям обнаружить этот предполагаемый эффект, применяя набор правил, характеризующих совместные диалоги. Например, «закрыть окно?» следует интерпретировать как запрос, а не как приказ.
Широко используемые библиотеки НЛП
На рынке доступно множество библиотек, пакетов, инструментов. У каждого из них есть свои плюсы и минусы.Как рыночная тенденция Python — это язык с наиболее совместимыми библиотеками. В таблице ниже представлен краткий обзор функций некоторых широко используемых библиотек. Большинство из них предоставляют базовые возможности НЛП, которые мы обсуждали ранее. Каждая библиотека NLP была построена с определенными целями, поэтому совершенно очевидно, что одна библиотека может не предоставлять решения для всего, их должен использовать разработчик, и именно здесь опыт и знания имеют значение, когда и где что использовать.
Практика NLP по использованию Python NLTK (простые примеры)
NLTK — ведущая платформа для создания программ Python для работы с данными на человеческом языке. Он предоставляет простые в использовании интерфейсы для более чем 50 корпоративных и лексических ресурсов.
Последняя версия: выпуск NLTK 3.5: апрель 2020 г., добавлена поддержка Python 3.8, прекращена поддержка Python 2.
NLTK включает множество корпусов, игрушечных грамматик, обученных моделей и т. Д. Полный список размещен по адресу: http: // nltk.org / nltk_data /.
Прежде чем мы начнем экспериментировать с некоторыми методами, которые широко используются в задаче обработки естественного языка, давайте сначала приступим к установке.
Установка НЛТК
Если вы используете Windows, Linux или Mac, вы можете установить NLTK с помощью pip:
$ pip install nltk
При желании вы также можете использовать подсказку Anaconda.
$ conda установить nltk
Если все в порядке, это означает, что вы успешно установили библиотеку NLTK.После того, как вы установили NLTK, вы должны установить пакеты NLTK, запустив следующий код:
Откройте свой Jupyter Notebook и выполните следующие команды.
Это покажет загрузчику NLTK, чтобы выбрать, какие пакеты необходимо установить. Вы можете установить все пакеты, так как они имеют небольшой размер, поэтому нет проблем. А теперь давайте начнем шоу.
Основные операции НЛП: сделай сам
Токенизировать текст
Токенизация — это первый шаг в НЛП.Процесс разбиения абзаца текста на более мелкие части, такие как слова или предложения, называется токенизацией. Токен — это единый объект, который является строительным блоком для предложения или абзаца.
Слово (токен) — это минимальная единица, которую машина может понять и обработать. Таким образом, любая текстовая строка не может быть обработана без токенизации. Токенизация — это процесс разделения необработанной строки на значимые токены. Сложность токенизации зависит от потребностей приложения NLP и сложности самого языка.Например, в английском языке это может быть так же просто, как выбрать только слова и числа с помощью регулярного выражения. Но для китайцев и японцев это будет очень сложная задача.
Токенизация предложения
Токенизатор предложений разбивает текстовый абзац на предложения.
Токенизация слов
Токенизатор Word разбивает текстовый абзац на слова.
Удаление стоп-слов
стоп-слов рассматриваются как шум в тексте.Текст может содержать такие стоп-слова, как is, am, are, this, a, an, the и т. Д.
Мы бы не хотели, чтобы эти слова занимали место в нашей базе данных или драгоценное время обработки. Для этого мы можем легко удалить их, сохранив список слов, которые вы считаете стоп-словами. NLTK (Natural Language Toolkit) в python имеет список стоп-слов, хранящихся на 16 разных языках.
Вы можете видеть, что слова is, my были удалены из предложения.
Разметка части речи
В детстве вы, возможно, слышали термин «Часть речи» (POS).На то, чтобы понять, что такое прилагательные и наречия, действительно может потребоваться немало времени. В чем именно разница? Подумайте о создании системы, в которой мы сможем закодировать все эти знания. Это может показаться очень простым, но на протяжении многих десятилетий кодирование этих знаний в модели машинного обучения было очень сложной проблемой НЛП. Алгоритмы тегов POS могут предсказать POS данного слова с более высокой степенью точности. Вы можете получить POS отдельных слов в виде кортежа
Если вы хотите узнать подробности POS, вот способ.Обратите внимание, что нам может потребоваться загрузить «набор тегов». Пример ниже показывает, что NN — существительное.
Для лучшего понимания ниже приведен другой POS, который мы нашли в нашем примере.
Значения всех доступных POS-кодов приведены ниже для справки.
Теперь рассмотрим интересный вопрос о поиске информации с использованием тегов POS. Я получил статью о крикете, пытаюсь посмотреть, какие страны упомянуты в документе.Названия стран являются существительными собственными, поэтому с помощью POS я могу легко фильтровать и получать только имена собственные. Помимо стран, он может извлекать больше слов, которые являются существительными собственными, но это упрощает нашу работу, поскольку ни одно название страны не будет пропущено.
Стемминг и лемматизация
Лемматизация — это процесс преобразования слова в его основную форму. Разница между выделением корней и лемматизацией заключается в том, что лемматизация учитывает контекст и преобразует слово в его значимую базовую форму, тогда как выделение корней просто удаляет последние несколько символов, что часто приводит к неправильному значению и орфографическим ошибкам.
В зависимости от области применения вы можете выбрать любой из представленных ниже лемматизаторов
- Лемматизатор Wordnet
- Просторный лемматизатор
- TextBlob
- Образец ЗАЖИМОВ
- Стэнфордский CoreNLP
- Лемматизатор Gensim
- TreeTagger
Вот один быстрый пример использования лемматизатора Wordnet.
Как узнать значения слов, синонимы и антонимы
WordNet — большая лексическая база данных английского языка.Это широко используемый корпус НЛТК. Существительные, глаголы, прилагательные и наречия сгруппированы в наборы когнитивных синонимов (синсетов), каждый из которых выражает отдельное понятие. Синсеты связаны между собой понятийно-семантическими и лексическими отношениями.
Структура WordNet делает его полезным инструментом для компьютерной лингвистики и обработки естественного языка.
Вы можете просто импортировать, используя
из nltk.corpus импорт Wordnet
В приведенном ниже простом примере давайте попробуем увидеть, насколько легко мы можем получить синоним и антоним слова «любовь».Это действительно круто!
Рабочая частота: быстрая визуализация
В приведенном ниже примере давайте попробуем прочитать текст с живого URL и посмотреть, как часто встречаются слова.
НЛП, какое будущее?
Как мы видели, НЛП предоставляет широкий набор техник и инструментов, которые можно применять во всех сферах жизни. Изучая их и используя их в повседневном общении, качество нашей жизни значительно улучшится, а также мы сможем улучшить жизнь тех, кто нас окружает.
техники НЛП помогают нам улучшить наше общение, достижение наших целей и результаты, которые мы получаем от каждого взаимодействия. Также они позволяют преодолевать личные препятствия и психологические проблемы. НЛП помогает нам использовать инструменты и техники, которые у нас уже есть, но не осознавать этого.
Все стало намного быстрее и лучше, потому что теперь мы можем общаться с машинами благодаря технологии обработки естественного языка. Обработка естественного языка дала крупным компаниям возможность гибко принимать решения благодаря анализу таких аспектов, как настроения клиентов и рыночные сдвиги.Умные организации теперь принимают решения, основываясь не только на данных, но и на интеллекте, полученном из этих данных машинами, работающими с НЛП.
По мере того, как в будущем НЛП становится все более популярным, может произойти массовый сдвиг в сторону этого основанного на интеллекте способа принятия решений на глобальных рынках и в разных отраслях.
Если есть что-то, что, как мы можем гарантировать, произойдет в будущем, так это интеграция обработки естественного языка почти во все аспекты жизни, какими мы их знаем. Последние пять лет были медленным сжиганием того, на что способно НЛП, благодаря интеграции со всеми видами устройств, от компьютеров и холодильников до динамиков и автомобилей.
Люди, например, проявили больше энтузиазма, чем неприязнь к процессу взаимодействия человека с машиной. Инструменты, основанные на НЛП, также доказали свои способности за такое короткое время.
Эти факторы приведут к усилению интеграции НЛП: постоянно растущие объемы данных, генерируемых в ходе деловых операций по всему миру, увеличение использования интеллектуальных устройств и повышение спроса на расширенные услуги со стороны клиентов.
Что касается обработки естественного языка, нет предела. В будущем нас ждут серьезные изменения, поскольку технология становится все более популярной и исследуются возможности для дальнейшего развития.Как главный аспект искусственного интеллекта, обработка естественного языка также будет способствовать пресловутому вторжению роботов на рабочие места, поэтому отрасли во всем мире должны начать подготовку.
Артикулы:
Книги
- Обработка естественного языка с помощью Python — Авторы Стивен Берд, Юэн Кляйн и Эдвард Лопер. О’Рейли.
- Обработка естественного языка: путь обучения Python и NLTK — Авторы: Нитин Хардения, Джейкоб Перкинс, Дипти Чопра, Нишит Джоши, Ити Матур.Упаковка
- Text Analytics с Python: практический подход к получению практической информации из ваших данных от Дипанджана Саркара. Апресс
- NLTK Essentials от Нитина Хардения. Упаковка
- Рецепты обработки естественного языка: разблокирование текстовых данных с помощью машинного обучения и глубокого обучения с использованием Python, Акшай Кулкарни, Адарша Шивананда. Апресс
Сайты
Введение в обработку естественного языка (NLP)
Обработка естественного языка (NLP) — это область информатики и искусственного интеллекта, связанная с взаимодействием между компьютерами и людьми на естественном языке. Конечная цель НЛП — помочь компьютерам понимать язык так же хорошо, как и мы. Это движущая сила таких вещей, как виртуальные помощники, распознавание речи, анализ тональности, автоматическое суммирование текста, машинный перевод и многое другое. В этом посте мы рассмотрим основы обработки естественного языка, погрузимся в некоторые из ее методов, а также узнаем, как НЛП помогло последним достижениям в области глубокого обучения.
Содержание
- Введение
- Почему НЛП сложно
- Синтаксический и семантический анализ
- Техники НЛП
- Глубокое обучение и NLP
- Список литературы
И.Введение
Обработка естественного языка (NLP) — это пересечение информатики, лингвистики и машинного обучения. Эта область фокусируется на общении между компьютерами и людьми на естественном языке, а НЛП — на том, чтобы заставить компьютеры понимать и генерировать человеческий язык. Применения методов НЛП включают голосовых помощников, таких как Amazon Alexa и Apple Siri, а также такие вещи, как машинный перевод и фильтрация текста.
NLP сильно выиграл от последних достижений в области машинного обучения, особенно от методов глубокого обучения.Поле разделено на три части:
- Распознавание речи — Перевод устной речи в текст.
- Понимание естественного языка — Способность компьютера понимать то, что мы говорим.
- Генерация естественного языка — Генерация естественного языка компьютером.
II. Почему НЛП — это сложно
Человеческий язык особенный по нескольким причинам. Он специально разработан, чтобы передать смысл говорящего / писателя.Это сложная система, хотя маленькие дети могут освоить ее довольно быстро.
Еще одна замечательная черта человеческого языка — это то, что все дело в символах. По словам Криса Мэннинга, профессора машинного обучения из Стэнфорда, это дискретная, символическая, категориальная сигнальная система. Это означает, что мы можем передавать одно и то же значение разными способами (например, речь, жест, знаки и т. Д.). Кодирование человеческим мозгом — это непрерывный паттерн активации, посредством которого символы передаются через непрерывные звуковые и визуальные сигналы.
Понимание человеческого языка считается сложной задачей из-за его сложности. Например, существует бесконечное количество различных способов расположить слова в предложении. Кроме того, слова могут иметь несколько значений, и для правильной интерпретации предложений необходима контекстная информация. Каждый язык более или менее уникален и неоднозначен. Достаточно взглянуть на следующий заголовок в газете «Папа папа наступает на геев». Это предложение явно имеет две очень разные интерпретации, что является довольно хорошим примером проблем в НЛП.
Обратите внимание, что идеальное понимание языка компьютером привело бы к созданию ИИ, способного обрабатывать всю информацию, доступную в Интернете, что, в свою очередь, вероятно, привело бы к созданию общего искусственного интеллекта.
III. Синтаксический и семантический анализ
Синтаксический анализ (синтаксис) и семантический анализ (семантический) — два основных метода, которые приводят к пониманию естественного языка. Язык — это набор правильных предложений, но что делает предложение действительным? Синтаксис и семантика.
Синтаксис — это грамматическая структура текста, а семантика — это передаваемое значение. Однако синтаксически правильное предложение не всегда является семантически правильным. Например, фраза «коровы в высшей степени текут» грамматически корректна (подлежащее — глагол — наречие), но не имеет никакого смысла.
Синтаксический анализ
Синтаксический анализ, также называемый синтаксическим анализом или синтаксическим анализом, — это процесс анализа естественного языка с использованием правил формальной грамматики.Грамматические правила применяются к категориям и группам слов, а не к отдельным словам. Синтаксический анализ в основном придает тексту семантическую структуру.
Например, предложение включает подлежащее и сказуемое, где подлежащее — это существительная фраза, а предикат — глагольная фраза. Взгляните на следующее предложение: «Собака (существительная фраза) ушла (глагольная фраза)». Обратите внимание, как мы можем комбинировать каждую именную фразу с глагольной фразой. Опять же, важно повторить, что предложение может быть синтаксически правильным, но не иметь смысла.
Семантический анализ
То, как мы понимаем сказанное кем-то, — это бессознательный процесс, основанный на нашей интуиции и знаниях о самом языке. Другими словами, то, как мы понимаем язык, во многом зависит от значения и контекста. Однако к компьютерам нужен другой подход. Слово «семантический» является лингвистическим термином и означает «относящийся к значению или логике».
Семантический анализ — это процесс понимания значения и интерпретации слов, знаков и структуры предложения.Это позволяет компьютерам частично понимать естественный язык так, как это делают люди. Я говорю отчасти потому, что семантический анализ — одна из самых сложных частей НЛП, и она еще не решена полностью.
Распознавание речи, например, стало очень хорошим и работает почти безупречно, но нам все еще не хватает такого уровня знаний в понимании естественного языка. Ваш телефон в основном понимает то, что вы сказали, но часто ничего не может с этим поделать, потому что не понимает стоящего за этим смысла. Кроме того, некоторые технологии только заставляют вас думать, что они понимают значение текста.Подход, основанный на ключевых словах или статистике, или даже на чистом машинном обучении, может использовать метод сопоставления или частоты для подсказок относительно того, «о чем» текст. Эти методы ограничены, потому что они не рассматривают истинный смысл.
IV. Методы понимания текста
Давайте рассмотрим некоторые из самых популярных методов, используемых при обработке естественного языка. Обратите внимание, как некоторые из них тесно взаимосвязаны и служат только в качестве подзадач для решения более крупных проблем.
Разбор
Что такое парсинг? Согласно словарю, синтаксический анализ означает «разложить предложение на составные части и описать их синтаксические роли».
Это на самом деле прибило, но могло бы быть немного более исчерпывающим. Под синтаксическим анализом понимается формальный анализ предложения компьютером на его составные части, результатом которого является дерево синтаксического анализа, показывающее их синтаксические отношения друг с другом в визуальной форме, которое можно использовать для дальнейшей обработки и понимания.
Ниже представлено дерево синтаксического анализа для предложения «Вор ограбил квартиру». Включено описание трех различных типов информации, передаваемых в предложении.
Буквы непосредственно над отдельными словами показывают части речи для каждого слова (существительное, глагол и определитель). Уровень выше — это некая иерархическая группировка слов во фразы. Например, «вор» — это существительное, «ограбил квартиру» — глагольное словосочетание, и, сложив вместе эти две фразы, образуют предложение, которое отмечается на один уровень выше.
Но что на самом деле означает существительное или глагольная фраза? Существительные фразы — это одно или несколько слов, которые содержат существительное и, возможно, некоторые дескрипторы, глаголы или наречия. Идея состоит в том, чтобы сгруппировать существительные со словами, которые к ним относятся.
Дерево синтаксического анализа также предоставляет нам информацию о грамматических отношениях слов из-за структуры их представления. Например, мы можем видеть в структуре, что «вор» является субъектом «ограблен».
Под структурой я подразумеваю, что у нас есть глагол («ограблен»), который отмечен буквой «V» над ним и буквой «VP» над ним, которая связана буквой «S» с подлежащим («вор» ), над которым есть «NP».Это похоже на шаблон для отношений подлежащее-глагол, и есть много других для других типов отношений.
Ствол
Стемминг — это метод, основанный на морфологии и поиске информации, который используется в НЛП для предварительной обработки и повышения эффективности. В словаре это определяется как «происходить из или быть вызванным».
По сути, выделение корней — это процесс сокращения слов до их основы. «Основа» — это часть слова, которая остается после удаления всех аффиксов.Например, основа слова «тронут» — «прикоснуться». «Прикосновение» также является основой «прикосновения» и так далее.
Вы можете спросить себя, зачем нам вообще ствол? Итак, основа необходима, потому что мы встретимся с разными вариантами слов, которые на самом деле имеют одну основу и одно и то же значение. Например:
Я ехал на машине.
Я ехал в машине.
Эти два предложения означают одно и то же, и использование этого слова идентично.
А теперь представьте себе все английские слова в словаре со всеми их различными фиксациями в конце. Для их хранения потребуется огромная база данных, содержащая множество слов, которые на самом деле имеют одинаковое значение. Это решается путем сосредоточения внимания только на основе слова. Популярные алгоритмы выделения включают алгоритм вывода Портера из 1979 года, который до сих пор хорошо работает.
Сегментация текста
Сегментация текста в НЛП — это процесс преобразования текста в значимые единицы, такие как слова, предложения, различные темы, лежащее в основе намерение и многое другое.В основном текст разбивается на составляющие слова, что может быть сложной задачей в зависимости от языка. Это опять же из-за сложности человеческого языка. Например, в английском языке относительно хорошо работает разделение слов пробелами, за исключением таких слов, как «icebox», которые принадлежат друг другу, но разделены пробелом. Проблема в том, что люди иногда также пишут это как «ледяной ящик».
Признание именной организации
Распознавание именованных сущностей (NER) концентрируется на определении того, какие элементы в тексте (т.е. «именованные объекты») могут быть расположены и классифицированы по заранее определенным категориям. Эти категории могут варьироваться от имен людей, организаций и местоположений до денежных значений и процентов.
Например:
До NER: Мартин купил 300 акций SAP в 2016 году.
После NER: [Мартин] Человек купил 300 акций [SAP] Organization за [2016] Время.
Извлечение отношений
Извлечение отношений берет названные объекты NER и пытается идентифицировать семантические отношения между ними.Это может означать, например, выяснение, кто с кем женат, что человек работает в определенной компании и так далее. Эта проблема также может быть преобразована в проблему классификации, и модель машинного обучения может быть обучена для каждого типа отношений.
Анализ тональности
С помощью анализа настроений мы хотим определить отношение (то есть настроение) говорящего или писателя по отношению к документу, взаимодействию или событию. Следовательно, это проблема обработки естественного языка, когда текст необходимо понимать, чтобы предсказать основное намерение.Настроения в основном делятся на положительные, отрицательные и нейтральные категории.
С помощью анализа настроений, например, мы можем захотеть спрогнозировать мнение и отношение клиента к продукту на основе написанного ими обзора. Анализ тональности широко применяется к обзорам, опросам, документам и многому другому.
Если вам интересно использовать некоторые из этих методов с Python, взгляните на Jupyter Notebook о наборе инструментов естественного языка Python (NLTK), который я создал.Вы также можете ознакомиться с моим сообщением в блоге о построении нейронных сетей с помощью Keras, где я обучаю нейронную сеть выполнять анализ настроений.
V. Глубокое обучение и НЛП
Центральное место в глубоком обучении и естественном языке занимает «значение слова», когда слово и особенно его значение представлены в виде вектора действительных чисел. С помощью этих векторов, которые представляют слова, мы помещаем слова в многомерное пространство. Интересно то, что слова, представленные векторами, будут действовать как семантическое пространство.Это просто означает, что слова, которые похожи и имеют похожее значение, имеют тенденцию группироваться вместе в этом многомерном векторном пространстве. Вы можете увидеть визуальное представление значения слова ниже:
Вы можете узнать, что означает группа сгруппированных слов, выполнив анализ главных компонентов (PCA) или уменьшение размерности с помощью T-SNE, но иногда это может вводить в заблуждение, поскольку они упрощают и оставляют много информации на стороне. Это хороший способ начать работу (например, логистическая или линейная регрессия в науке о данных), но он не является передовым и можно сделать это лучше.
Мы также можем думать о частях слов как о векторах, которые представляют их значение. Представьте себе слово «нежелательность». Используя морфологический подход, который включает в себя различные части слова, мы могли бы думать, что оно состоит из морфем (частей слова), например: «Un + желание + способность + ity». Каждая морфема получает свой вектор. Исходя из этого, мы можем построить нейронную сеть, которая может составить значение более крупной единицы, которая, в свою очередь, состоит из всех морфем.
Глубокое обучение также может определять структуру предложений с помощью синтаксических анализаторов.Google использует подобные методы анализа зависимостей, хотя и в более сложной и широкой манере, с их «McParseface» и «SyntaxNet».
Зная структуру предложений, мы можем начать пытаться понять смысл предложений. Мы начинаем со значения слов, являющихся векторами, но мы также можем сделать это с целыми фразами и предложениями, где значение также представлено в виде векторов. И если мы хотим знать взаимосвязь предложений или между ними, мы обучаем нейронную сеть принимать эти решения за нас.
Глубокое обучение также хорошо подходит для анализа настроений. Возьмем, к примеру, этот обзор фильма: «В этом фильме нет дела до ума, с каким-либо другим умным юмором». Традиционный подход попался бы в ловушку, думая, что это положительный отзыв, потому что «сообразительность или любой другой вид интеллектуального юмора» звучит как положительное намерение, но нейронная сеть распознала бы его реальное значение. Другие приложения — это чат-боты, машинный перевод, Siri, предлагаемые ответы в почтовом ящике Google и так далее.
Также произошел огромный прогресс в машинном переводе благодаря появлению рекуррентных нейронных сетей, о которых я также написал сообщение в блоге.
В машинном переводе, выполняемом с помощью алгоритмов глубокого обучения, язык переводится, начиная с предложения и генерируя векторные представления, которые его представляют. Затем он начинает генерировать слова на другом языке, содержащие ту же информацию.
Подводя итог, НЛП в сочетании с глубоким обучением — это все о векторах, которые представляют слова, фразы и т. Д.и до некоторой степени их значения.
VI. Список литературы
Никлас Донгес — предприниматель, технический писатель и эксперт в области искусственного интеллекта. В течение 1,5 лет он работал в команде SAP в области искусственного интеллекта, после чего основал компанию Markov Solutions. Компания из Берлина специализируется на искусственном интеллекте, машинном обучении и глубоком обучении, предлагая индивидуальные программные решения на базе искусственного интеллекта и консалтинговые программы для различных компаний.
СвязанныеПодробнее о Data Science
Stanford CS 224N | Обработка естественного языка с глубоким обучением
Курсовая работа
Переуступки (54%)
Есть пять еженедельных заданий, которые улучшат ваше теоретическое понимание и ваши практические навыки.Все задания содержат как письменные вопросы, так и программные части. В рабочее время администраторы курсов могут просматривать коды учащихся для заданий 1, 2 и 3, но не для заданий 4 и 5.
- Кредит :
- Задание 1 (6%): Знакомство с векторами слов
- Задание 2 (12%): Производные и реализация алгоритма word2vec
- Задание 3 (12%): анализ зависимостей и основы нейронной сети
- Задание 4 (12%): нейронный машинный перевод с последовательностью, вниманием и подсловами
- Задание 5 (12%): Самостоятельное обучение и точная настройка с помощью трансформаторов
- Сроки : Все задания должны быть выполнены во вторник или четверг до начала занятий (т.е. до 16:30). Все сроки указаны в расписании.
- Submission : Задания отправляются через Gradescope. Если вам необходимо зарегистрировать учетную запись Gradescope, используйте свой адрес электронной почты @ stanford.edu . Дальнейшие инструкции даются в раздаточном материале каждого задания. Не присылайте нам свои задания по электронной почте .
- Позднее начало : Если результат дает вам более высокую оценку, мы не будем использовать ваш балл за задание 1, и мы дадим вам оценку за задание, основанную на подсчете каждого из заданий 2–5 на 13.5%.
- Сотрудничество : Разрешены учебные группы, но студенты должны понимать и выполнять свои собственные задания и сдавать по одному заданию на каждого студента. Если вы работали в группе, пожалуйста, укажите имена членов вашей учебной группы в верхней части вашего задания. Спрашивайте, есть ли у вас какие-либо вопросы о политике сотрудничества.
- Код чести : Мы ожидаем, что студенты не будут смотреть на решения или реализации в Интернете. Как и все другие классы в Стэнфорде, мы серьезно относимся к Кодексу чести учащихся.
Заключительный проект (43%)
Заключительный проект предлагает вам возможность применить свои недавно приобретенные навыки для более глубокого применения. У студентов есть два варианта: финальный проект по умолчанию (в котором учащиеся решают заранее определенную задачу, а именно текстовые ответы на вопросы) или пользовательский финальный проект (в котором учащиеся выбирают свой собственный проект, включающий естественный язык и глубокое обучение). Примеры того и другого можно увидеть на прошлогоднем сайте.
Важная информация
- Кредит : Как для стандартных, так и для пользовательских проектов кредит для окончательного проекта разбивается следующим образом:
- Сроки : Предложение по проекту, этап и отчет должны быть представлены в 16:30. Все сроки указаны в расписании.
- Финальный проект по умолчанию [раздаточный материал (дорожка IID SQuAD)] [раздаточный материал (дорожка надежного контроля качества)] [слайды лекций]: В этом проекте студенты изучают решения для глубокого обучения для задачи SQuAD (Stanford Question Asking Dataset).В этом году проект аналогичен прошлогоднему, на SQuAD 2.0 с базовым кодом в PyTorch.
- Советы по проекту [слайды лекций] [конспекты лекций]: Лекция «Практические советы для финальных проектов» содержит рекомендации по выбору и планированию проекта. Чтобы получить совет от сотрудников по проекту, сначала посмотрите на области знаний каждого сотрудника на странице рабочего времени. Это должно помочь вам найти сотрудника, знающего о вашей области проекта.
Практические аспекты
- Размер команды : студенты могут выполнять заключительные проекты самостоятельно или в группах до 3 человек. Настоятельно рекомендуем делать финальный проект в команде. Ожидается, что более крупные команды будут выполнять соответственно более крупные проекты, и вам следует формировать команду из 3 человек только в том случае, если вы планируете реализовать амбициозный проект, в котором каждый член команды внесет значительный вклад.
- Вклад : В окончательном отчете мы просим указать, что каждый член команды внес в проект.Члены команды обычно получают одинаковую оценку, но мы можем различать в крайних случаях неравного вклада. Вы можете конфиденциально связаться с нами в случае неравного взноса.
- Внешние соавторы : Вы можете работать над проектом, в котором есть внешние соавторы (не учащиеся CS224n), но вы должны четко указать в своем итоговом отчете, какие части проекта были вашей работой.
- Совместное использование проектов : Вы можете совместно использовать один проект между CS224n и другим классом, но мы ожидаем, что проект будет соответственно больше, и вы должны заявить, что вы разделяете проект в своем предложении по проекту.
- Наставники : У каждой индивидуальной проектной команды есть наставник, который дает обратную связь и дает советы во время проекта. У проектных команд по умолчанию нет наставников. У проекта может быть внешний наставник (т. Е. Не сотрудники курса); в противном случае мы назначим наставника CS224n для индивидуальных проектных групп после предложений по проектам.
- Вычислительные ресурсы : Все команды получат кредиты на использование службы облачных вычислений Azure.
- Использование внешних ресурсов : Следующие рекомендации применимы ко всем проектам (хотя проект по умолчанию имеет некоторые более конкретные правила, представленные в разделе Кодекс чести раздаточного материала (IID SQuAD track) и раздаточного материала (Robust QA track)):
- Вы можете использовать любую структуру глубокого обучения, которая вам нравится (PyTorch, TensorFlow и т. Д.)
- В более общем плане, вы можете использовать любой существующий код, библиотеки и т. Д., А также обращаться к любым документам, книгам, онлайн-ссылкам и т. Д. Для своего проекта. Тем не менее, вы должны указать свои источники в своем отчете и четко указать, какие части проекта являются вашим вкладом, а какие части были реализованы другими.
- Ни при каких обстоятельствах вы не можете просматривать код другой группы CS224n или включать их код в свой проект.
Участие (3%)
Благодарим всех за активное участие в уроке! Есть несколько способов заработать кредит участия, который ограничен 3%:
- Посещение лекций приглашенных докладчиков :
- Во второй половине класса у нас есть три приглашенных докладчика.Наши приглашенные докладчики прилагают значительные усилия, чтобы выступить для нас с лекциями, поэтому (чтобы выразить нашу признательность и продолжить привлекать интересных спикеров) мы не хотим, чтобы они читали лекции в пустой комнате. Таким образом, мы поощряем студентов посещать эти виртуальные лекции вживую и участвовать в вопросах и ответах.
- Все учащиеся получают 0,5% за выступающего (всего 1,5%), написав параграф-реакцию, основанную на просмотре выступления; подробности будут предоставлены. Студентам не нужно посещать лекцию вживую, чтобы писать эти параграфы с реакциями; они могут смотреть асинхронно.
- Заполнение опросов отзывов : Мы разошлем два опроса (в середине и в конце квартала), чтобы помочь нам понять, как проходит курс и как мы можем улучшить. Стоимость каждого из двух опросов составляет 0,5%.
- Участие Эда : ~ 20 лучших участников Эда получат 3%; другие получат кредит пропорционально участию ~ 20-го человека.
- Очко кармы : Любое другое действие, которое улучшает класс, например помощь другому ученику в Укромных уголках, которое ТА CS224n или инструктор замечает и считает достойным: 1%
Поздние дни
- Каждому ученику дается 6 дополнительных дней.Поздний день продлевает срок на 24 часа. Вы можете использовать до 3 дней просрочки для каждого задания (включая все пять заданий, проектное предложение, контрольную точку проекта, заключительный отчет по проекту и резюме проекта).
- Команды могут разделить между участниками поздний день. Например, у группы из трех человек должно быть не менее шести поздних дней между ними, чтобы продлить крайний срок на два дня. Если сообщается о каких-либо поздних днях, это должно быть четко указано в начале отчета и заполнить форму, указанную в этой публикации Ed .
- После того, как вы использовали все 6 дней допоздна, штраф составляет 1% от итоговой оценки за каждый дополнительный день допоздна.
Запросы на повторное обновление
Если вы считаете, что заслужили более высокую оценку за задание, вы можете отправить запрос на повторную оценку в Gradescope в течение 3 дней после публикации оценок. В вашем запросе должно быть кратко изложено, почему вы считаете, что первоначальная оценка была несправедливой. Ваш TA пересмотрит ваше задание как можно скорее, а затем вынесет решение.Если вы все еще недовольны, вы можете попросить инструктора пересмотреть свое задание.
Кредит / Нет кредита
Если вы возьмете зачетный балл / без балла, то вы получите оценку так же, как и зарегистрированные для получения буквенного балла. Единственная разница в том, что если вы достигнете C-стандарта в своей работе, она будет просто оценена как CR.
Аудит курса
В целом, мы рады иметь аудиторов, если они являются членами Стэнфордского сообщества (зарегистрированный студент, официальный посетитель, персонал или преподавательский состав).Если вы действительно хотите усвоить материал класса, мы настоятельно рекомендуем аудиторам выполнять все задания. Однако из-за большого количества учащихся мы не можем оценивать работу учащихся, официально не зачисленных в класс.
Облачные вычисления на GPU
Мы благодарим Microsoft Azure за спонсирование облачных вычислений на GPU для учащихся этого класса.
Приглашаем всех студентов
Мы стремимся делать все возможное, чтобы работать на справедливость и создать инклюзивную среду обучения, которая активно ценит разнообразие происхождения, идентичности и опыта каждого в CS224N.Мы также знаем, что иногда делаем ошибки. Если вы заметите, что мы могли бы сделать лучше, мы надеемся, что вы сообщите об этом кому-нибудь из сотрудников курса.
Благополучие и психическое здоровье
Последние двенадцать месяцев были трудными для всех. Мы здесь для того, чтобы помочь вам пережить еще пару кварталов пандемии. Если вы испытываете личные, академические проблемы или проблемы во взаимоотношениях и хотите поговорить с кем-то, имеющим образование и опыт, обратитесь в Консультационно-психологическую службу (CAPS) на территории кампуса.CAPS — университетский консультационный центр, посвященный психическому здоровью и благополучию студентов. Назначить встречу по телефону для оценки можно в CAPS по телефону 650-723-3785 или через портал VadenPatient через веб-сайт Vaden.
Студенты-инвалиды
Если вам необходимо учебное жилье по причине инвалидности, вам следует подать запрос в Управление доступного образования (OAE). OAE оценит запрос, порекомендует жилье и подготовит письмо для преподавателей.Студенты должны связаться с OAE как можно скорее и, в любом случае, до крайних сроков назначения, так как своевременное уведомление необходимо для согласования приспособлений. Студенты также должны как можно скорее отправить письмо о проживании инструкторам.
Сексуальное насилие
Академические условия доступны для студентов, которые испытали или восстанавливаются от сексуального насилия. Если вы хотите поговорить с конфиденциальным ресурсом, вы можете назначить встречу с командой конфиденциальной поддержки или позвонить на их круглосуточную горячую линию по телефону: 650-725-9955.Консультационные и психологические службы также предлагают конфиденциальные консультационные услуги. Неконфиденциальные ресурсы включают Офис Титула IX, для расследования и размещения, и Офис SARA, для программ лечения. Студенты также могут напрямую поговорить с преподавательским составом, чтобы договориться о размещении. Обратите внимание, что сотрудники университета, в том числе профессора и технические специалисты, обязаны сообщать все, что им известно о случаях сексуального насилия или насилия в отношениях, преследовании и сексуальных домогательствах, в офис Title IX.