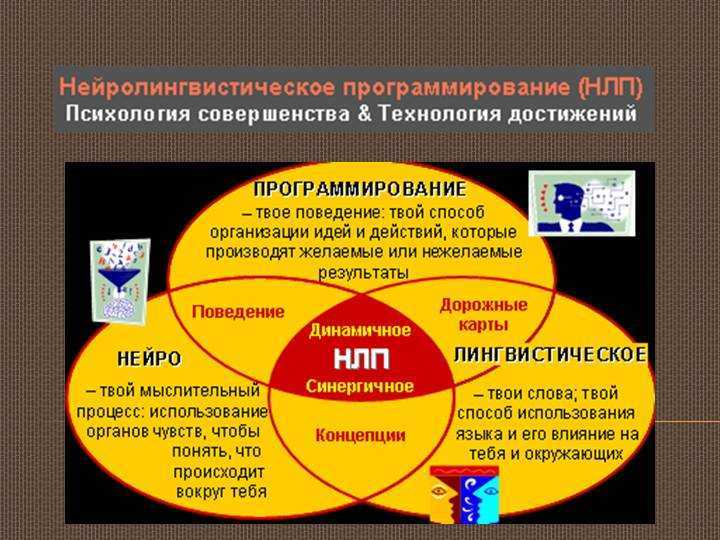
НЛП что это такое в психологии
Что такое НЛП?
Никто из нас не рождается с готовыми инструкциями по эксплуатации мозга. Несмотря на это, существуют эффективные способы добиться желаемого как в работе, так и в личной жизни, используя интеллектуальный ресурс. Следуйте за собственными мечтами, покоряйте вершины, используйте максимальный потенциал вашей личности. Запомните, что единственное препятствие на пути к цели — это вы сами.
Нейролингвистическое программирование (НЛП) — универсальное руководство для грамотного использования собственных ресурсов в достижении целей. Это прикладная психология, позволяющая понять, как работает ум, каким образом образуются мысли и на их основе формируются шаблоны поведенческих реакций. Зная эти процессы в деталях, вы сможете исключить лишние паттерны поведения, которые тормозят вас на пути к успеху.
Каждый из нас обладает той или иной долей перфекционизма. Это стремление к совершенству активизируется на определенном этапе жизни.
В дословном переводе аббревиатура НЛП включает несколько понятий. В их числе:
- Нейро — относится к мозговым процессам, содержит принципы сбора информации из внешнего мира с использованием 5 основных каналов, связанных с органами чувств.
- Лингвистика — изучение языковых особенностей. Это преобразование полученной извне информации, пропущенной через фильтр внутреннего понимания событий и явлений, выраженное в структуре языка.
- Программирование — способ контроля повседневных действий, интерпретации поведенческих особенностей, выбор путей преобразования действительности.
НЛП — это набор инструментов для личных изменений и развития. Наука предлагает способы понимания мира, окружающих нас людей, эффективные методы преобразования обстановки для более быстрого и легкого достижения целей. Это снятие неработающих паттернов поведения, техники преодоления проблем, трудностей, способов снижения стресса.
Наука предлагает способы понимания мира, окружающих нас людей, эффективные методы преобразования обстановки для более быстрого и легкого достижения целей. Это снятие неработающих паттернов поведения, техники преодоления проблем, трудностей, способов снижения стресса.
Краткая история НЛП
Нейролингвистическое программирование официально зародилось в Калифорнии в 1970-х годах, хотя корни философской практики простираются вглубь времен, уходя к истокам антропологии Грегори Бейтсона (1904-1980) и лингвистики Ноама Хомского (1928 г.р). Учение возродилось в рамках исследования терапевтических процессов, когда один из основателей НЛП Ричард Бэндлер заинтересовался, почему одни терапевты более эффективны в своих практиках, нежели другие деятели.
Ученый расшифровал записи сеансов Виржинии Сатир и Фрица Перлса. Эти транскрипты помог преобразовать Джон Гриндер, используя свой лингвистический опыт. В процессе работы были обнаружены модели «вмешательства», которые позже были закодированы в первый инструмент НЛП, названный Мета-моделью.
Следующим шагом стало изучение техник Милтона Эриксона, известного гипнотерапевта. Его действия только подтвердили силу Мета-модели и дали основания для выделения второго инструмента НЛП — модели Милтона. Начинаясь в качестве психотерапевтической практики, НЛП уверенно переросло направление. А его основатели стали совершенствовать и приумножать свои знания, используя метод в бизнесе, политике, спорте.
Наука действительно удивительна. Она гармонично комбинирует в себе множество знаний — от кибернетики до терапии, ориентированной на человеческую психику. Такие видные деятели, как Роберт Дилтс, Джудит де Лозье, Стивен Гиллиган, Стив и Конни Раэ Андреас создали ряд мощных моделей и приемов.
Не обошлось без критики. Впервые негативные отзывы НЛП появились, когда владеющие техникой люди стали достигать неимоверных высот в методах продаж и гипнотических воздействиях. Несмотря на это, метод развивался. Преимущественно он использовался для улучшения жизни людей, повышения их уровня успешности и эффективности.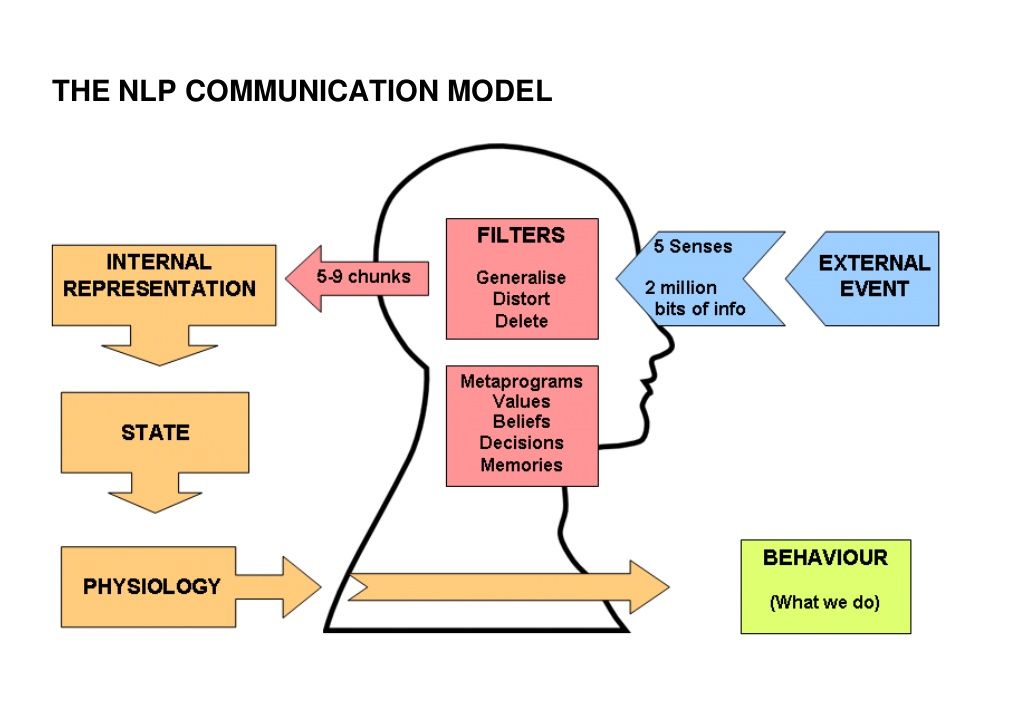
Что такое НЛП?
Задумывались ли вы над тем, чего вам не хватает в достижении желанных целей? Скорее всего, дело в привычках и отговорках, с которыми вы не хотите бороться. Практикующие силу НЛП люди используют язык для разрушения психических барьеров, которые мы бессознательно создаем для себя. Из-за этой уникальной возможности НЛП считается одним из самых полезных и доступных инструментов современной психологии.
NLP учит людей адаптироваться к меняющимся условиям, преобразовывать действительность, чтобы жить той жизнью, о которой они мечтают. Тренер работает с клиентом, чтобы побудить его покинуть зону комфорта. Разрушение барьеров и возможность выбора оптимального пути помогают обрести более полную и счастливую жизнь.
Хотя нейролингвистическое программирование представляет собой обширную и сложную технику, фундаментальные идеи, лежащие в основе научного учения, можно разделить на три части:
- Субъективность — в основе лежит понимание того, что каждый имеет уникальную перспективу мира, в котором мы живем.
- Карты — убеждение, что наши собственные миры состоят из сложных территорий и границ, которые притягиваются к человеку, по мере его личностного роста.
- Язык — каждый человек имеет право переносить и трансформировать свои территории и границы с помощью систем управления. Самая влиятельная система, к которой мы имеем неограниченный доступ — это наш язык.
НЛП и субъективность
Представим следующую ситуацию: два человека оказались лишними на своих рабочих местах. Из-за отсутствия работы они были вынуждены покинуть свой район проживания для поиска новых возможностей. Лицо А изначально расстроилось неожиданными переменами, но свыклось с мыслями поиска альтернатив. Большую часть своего свободного времени оно тратило на поиск нового дома, налаживание новых социальных контактов и связей. В итоге оказалось, что новая работа давала меньше дохода по сравнению с предыдущей, но при этом коммунальные услуги за счет покупки дома в другом городе выходили более экономными, поэтому появились деньги на излишества и даже элементы роскоши. Изучив ситуацию со всех сторон, человек А понял, что сумел превратить потенциальный удар по собственному благополучию в новый позитивный опыт.
Большую часть своего свободного времени оно тратило на поиск нового дома, налаживание новых социальных контактов и связей. В итоге оказалось, что новая работа давала меньше дохода по сравнению с предыдущей, но при этом коммунальные услуги за счет покупки дома в другом городе выходили более экономными, поэтому появились деньги на излишества и даже элементы роскоши. Изучив ситуацию со всех сторон, человек А понял, что сумел превратить потенциальный удар по собственному благополучию в новый позитивный опыт.
В отличие от него человек Б не преуспел. Увольнение с рабочего места стало для него ударом по самолюбию, самооценке, поэтому он чувствовал, что новая работа (более низкого ранга) — явный признак неудачи. Эта утрата уверенности в собственных силах вызвала некую отвлеченность от происходящих вокруг процессов. К следующему шагу в своей жизни человек Б был не готов. Он длительно лелеял ощущение грусти, поэтому принял быстрое решение о покупке дома, когда подвернулось неплохое, на его взгляд, предложение. В итоге оказалось, что дом намного меньше предыдущего, имеет множество недостатков при ближайшем рассмотрении. Испытав очередную неудачу лицо Б чувствует себя одиноким и злым в той ситуации, где он оказался.
В итоге оказалось, что дом намного меньше предыдущего, имеет множество недостатков при ближайшем рассмотрении. Испытав очередную неудачу лицо Б чувствует себя одиноким и злым в той ситуации, где он оказался.
Мораль этой истории заключается в том, что независимо от того, что происходит с человеком, нужно смотреть на ситуацию, как на опыт, который учит. Единственное препятствие на этом пути — это сложности в изменении точки зрения и видения окружающего мира.
Карты НЛП
Карты нейролингвистического программирования, также известные как модели, являются следующим компонентом сложной техники. Идея состоит в том, что у каждого человека есть уникальная карта, обозначающая путь жизни. Практикующие НЛП мастера используют идею карты, чтобы проиллюстрировать, как мы можем рассматривать представления о нашем собственном мире.
Если говорить упрощенно, можно подумать об этом, словно мы носим очки, которые показывают только определенные части света.
Язык и НЛП
Конечная теория, лежащая в основе тренинга НЛП, заключается в том, что человеку не нужно ограничивать рамками наши карты, программируя системы внутреннего контроля.
Язык дает нам уникальную возможность формулировать, выражать и сообщать окружающим мысли.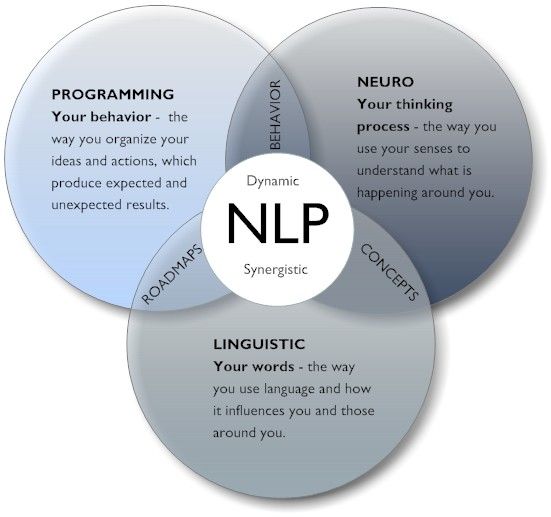 Он структурирует наш мир, а смысловое содержание и ассоциативные связи не только описывают, но и сами формируют реальность в окружающем нас пространстве.
Он структурирует наш мир, а смысловое содержание и ассоциативные связи не только описывают, но и сами формируют реальность в окружающем нас пространстве.
Изменяя практики использования языка, человек может расширить границы своих карт и сделать первые шаги, чтобы начать изменения, к которым он стремится. Иногда стоит остановиться и подумать о простых расшифровках слов. Например, задумайтесь, что означает для вас слово «неудача»? Для некоторых людей это слово представляет разочарование, печаль, ощущение тяжести в желудке. Эти ассоциации можно изменить, начав связывать слово с новым стартом в жизни, начинаниями и жизненным опытом. Меняя слова, можно прийти к удивительной способности менять и трансформировать восприятие мира, собственное мышление.
Коучинг и НЛП
Люди обмениваются чувствами и ощущениями по-разному. Большинство этих чувств фактически передается бессознательно, через тон, темп речи, выражение лица, язык тела и слова. Мастера НЛП учат нас распознавать эти тонкие, бессознательные подсказки, чтобы мы понимали, как чувствуют себя входящие с нами во взаимодействие люди. Тренер легко раскрывает ментальную карту клиента, работает с ней, чтобы двигаться вперед.
Тренер легко раскрывает ментальную карту клиента, работает с ней, чтобы двигаться вперед.
На практике существует три наиболее распространенных типа ограничительных убеждений, которые человек накладывает сам на себя (свои действия, поступки):
- Безнадежность;
- Бесполезность;
- Беспомощность.
Люди легко настраиваются на неудачу, если постоянно блуждают в негативных мыслях. Такие комментарии, как «Я недостаточно хорош» или «Другие люди лучше меня» ограничивают шансы на успех. В процессе тренинга НЛП тренер развеивает негативные убеждения, задавая ряд простых вопросов:
- Почему вы считаете, что не заслуживаете счастья или успеха?
- Почему вам не удается справиться с поставленными целями?
- Что мешает вам реализовать свои мечты?
Ответы на эти вопросы помогают выявить чувства, вызывающие ограниченные убеждения. После этого тренер исследует и оспаривает ограничения, меняя негативные мысли клиента на позитивное восприятие реальности.
Чего ожидать от НЛП?
Методы, используемые разными специалистами, существенно отличаются друг от друга. однако стандартная коуч сессия НЛП следует одной базовой схеме. Первоначально тренер узнает, что клиент хочет изменить в себе, а также проблемы, которые человек хочет преодолеть. Пристальное внимание уделяется тому, как клиент говорит, поэтому дальнейшее обучение адаптируется к полученным ответам.
Коуч выполняет ряд упражнений вместе с участниками тренинга, чтобы определить карту жизни каждого из них. Замечая жесткие ограничения, тренер активизирует новые мыслительные процессы клиента, чтобы помочь ему расширить границы карты. Вместе с тем, человеку даются упражнения, с которыми он должен работать дома. Это поможет быстрее привыкнуть к методам НЛП. В то время, как основные неврологические изменения произойдут уже во время сеансов тренинга, может потребоваться дополнительное время на их усвоение. Это необходимо для того, чтобы полученные приемы так же эффективно работали, когда клиент возвращается в повседневную жизнь.
Мастер НЛП может попросить записать собственные чувства, которые возникали до, во время и после сеанса. Это поможет лучше понять достигнутых в процессе работы результатов. Необходимо четко фиксировать все изменения после начала тренинговых занятий. Когда эти вещи осознаются на глубинном уровне, клиент становится готовым к началу изменений.
Считается, что НЛП популярно из-за фокусировки на будущем. Однако это не так. Техника работает в области исследования возможностей человека, методов формирования принимаемых им решений, использовании опыта прошлых лет. Коучинг НЛП заключается в добавлении новых фактов: возможностей расширения восприятия в позитивном русле, которые происходят в карте жизни конкретных людей.
Очень часто нейролингвистическое программирование рассматривается, как набор конкретных инструментов для ума, однако это понятие гораздо шире. Учение преобразует все области жизни. Как минимум, технологии НЛП помогут вам справиться со следующими ситуациями:
- Тревога и стресс — коучинг эффективен в борьбе с чувствами стресса и тревоги, поскольку он идентифицирует образ мыслей, оказывающих давление на психику.
 Как только эти бессознательные образы распознаются, их можно оспорить.
Как только эти бессознательные образы распознаются, их можно оспорить. - Здоровье и благополучие — одна из самых важных идей, лежащих в основе НЛП, заключается в том, что ум и тело тесно связаны между собой. При выполнении определенных упражнений человек испытывает положительную психическую и физическую энергию. Улучшая наши представления о мире, мы тем самым улучшаем наше здоровье и благополучие.
- Страхи и фобии — НЛП хорошо известно, как способ помощи людям в борьбе с опасениями, фобиями, страхами. Как и в случае с тревожностью, техника помогает раскрыть мыслительный процесс при формировании иррационального страха. Технология меняет образ мышления таким образом, что вчерашний ужас перестает быть таковым, меняясь на вещи, которых смешно бояться.
- Отношения — основаны на коммуникации. Проблемы возникают, когда люди не выражают свои эмоции, не сообщают о своем дискомфорте или счастье. НЛП помогает человеку лучше узнать, как общаться с высокой долей эффективности.
 Понимание чувств другого человека позволяет понять, что люди могут иметь разные взгляды на жизнь. Ни одно мнение не является правильным или неправильным. С помощью нейролингвистического программирования тренеры развивают навыки эмпатии у людей, что помогает им строить прочные, длительные отношения.
Понимание чувств другого человека позволяет понять, что люди могут иметь разные взгляды на жизнь. Ни одно мнение не является правильным или неправильным. С помощью нейролингвистического программирования тренеры развивают навыки эмпатии у людей, что помогает им строить прочные, длительные отношения. - Уверенность — люди нередко идут на курсы НЛП для облегчения собственных страхов и ограничений. Используемые методы помогают человеку сломать старые стереотипы и привычки, чтобы открыть перед собой новые возможности. НЛП повышает уверенность человека, обучая его умению принимать решения, основанные на мечтах, а не ограничивающих его страхах.
- Бизнес — технология является отличным инструментом в понимании людей, способов общения и методов взаимодействия. Изучение этих основ помогает человеку улучшить свои базовые навыки, потребности сопереживания, что делает эффективным ведение переговоров с коллегами, сотрудниками, партнерами, менеджерами компании.

НЛП для управления персоналом
Многие программы используют НЛП в качестве базы для реализации обучающих приемов воздействия. Тренеры и коучи находят НЛП действенным инструментом при совершении следующих действий:
- Понимания и передачи невербальных сообщений;
- Замены языковых шаблонов;
- Развития взаимопонимания;
- Создания атмосферы неограниченных возможностей.
- Внедрения изменений в сознание участников обучающего процесса.
Рекомендован метод менеджерам для достижения эффективного взаимодействия с сотрудниками вверенного им подразделения. Технология помогает лучше понимать стиль общения окружающих людей, устанавливать четкие достижимые цели, не теряя сил на формирование «воздушных замков». Техники способствуют созданию и поддержанию мотивационной среды, атмосферы понимания персоналом ценностей организации, приоритетов работы, сопоставления их со своими ценностными ориентациями.
______________________________
Краткое резюме
НЛП — это наиболее естественный способ понять, как сделать выбор и получить благоприятные результаты. Мы предлагаем вам пройти курс обучения нейролингвистическим техникам в соответствии с поставленной перед вами целью трансформировать собственную карту мира в эффективную модель неограниченных возможностей. НЛП поможет, если вы:
Мы предлагаем вам пройти курс обучения нейролингвистическим техникам в соответствии с поставленной перед вами целью трансформировать собственную карту мира в эффективную модель неограниченных возможностей. НЛП поможет, если вы:
- Застряли в прошлом и не можете начать новую жизнь;
- Постоянно откладываете сроки выполнения важных проектов;
- Чувствуете себя подавленным, грустным, расстроенным и не знаете, в чем причина такой хандры;
- Хотите улучшить карьерные перспективы, заработать больше денег;
- Терпите неудачу в любом начинании;
- Неуверенны в себе, не можете убедить собеседника в своей правоте;
- Хотите улучшить отношения с противоположным полом, стать успешным в личной жизни;
- Мечтаете повысить продажи;
- Хотите улучшить умственную и физическую работоспособность;
- Стремитесь выявить барьеры, удерживающие вас от свободы и независимости.
Это всего несколько примеров того, как НЛП способно преобразить вашу жизнь.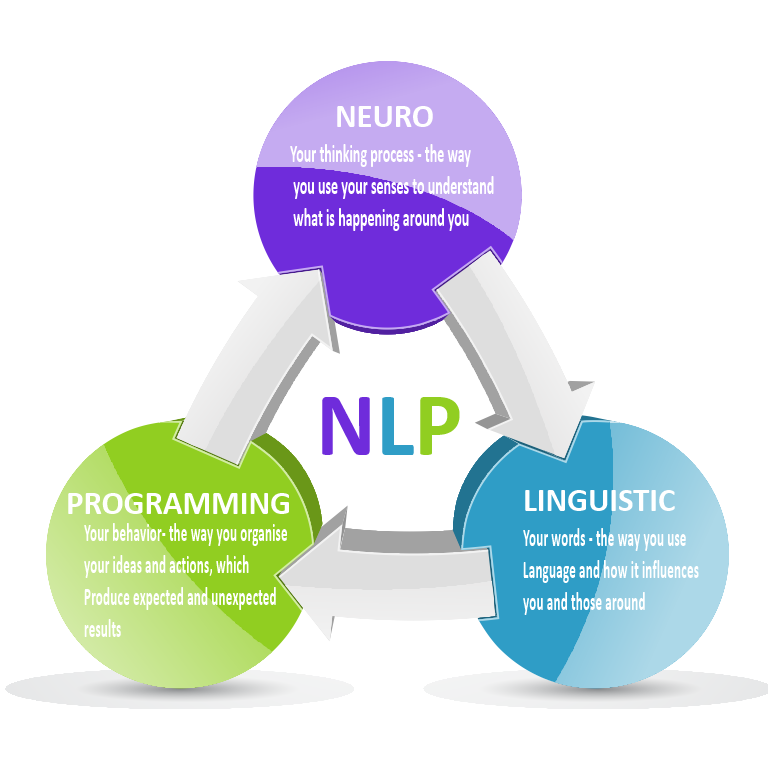 Не откладывайте изменения на завтра, если не хотите терять время на неудачи и ошибки. Звоните прямо сейчас, чтобы записаться на курсы НЛП под руководством профессионалов.
Не откладывайте изменения на завтра, если не хотите терять время на неудачи и ошибки. Звоните прямо сейчас, чтобы записаться на курсы НЛП под руководством профессионалов.
Что такое НЛП и работает ли оно
8 февраля 2022 Жизнь
Лайфхакер выяснил, можно ли, копируя поведение успешного человека, самому стать успешным.
О нейролингвистическом программировании (НЛП) говорят, о нём пишут книги и статьи. Многочисленные коучи предлагают свои услуги, обещая, что с помощью этого подхода вы достигнете небывалых высот в карьере и личной жизни. Но есть и альтернативное мнение, что НЛП — псевдонаучная концепция, используемая для вытягивания денег из доверчивых людей. Разбираемся, что же из этого правда.
Что такое НЛП
Нейролингвистическое программирование — подход к общению, самосовершенствованию и психотерапии. В более широком понимании это вера в то, что мы можем трансформировать свои и чужие убеждения, менять поведение, а также лечить психологические травмы с помощью специальных техник и упражнений.
В основе концепции НЛП лежит идея, что существует связь между неврологическими процессами, языком и паттернами поведения. Три этих компонента и отражены в термине:
- «нейро» — нервная система и мозг;
- «лингвистическое» — язык и речь;
- «программирование» — паттерны (шаблоны) поведения.
Из названия видно, что НЛП заимствует элементы различных наук: психологии, лингвистики, программирования, кибернетики. Также большое влияние на него оказали философские концепции конструктивизма и структурализма. Упрощённо их можно описать так: человек не пассивный наблюдатель, а творец этого мира, и изучать его нужно как сложный механизм.
Основным инструментом НЛП является моделирование — копирование образа жизни успешных людей, которых вы считаете примером для себя, вплоть до жестов, походки, одежды и голоса. Условно говоря, если вы хотите зарабатывать как Илон Маск, вы должны вести себя как Илон Маск, одеваться как Илон Маск, разговаривать, курить траву и писать в Twitter как Илон Маск.
Сейчас читают 🔥
- 10 убеждений, которые помогут противостоять манипуляциям
Кто, когда и зачем придумал НЛП
НЛП появилось в США в начале 70‑х годов. Его создателями стали студент‑психолог Ричард Бендлер и профессор лингвистики Джон Гриндер из Калифорнийского университета.
Бендлер увлекался компьютерами и программированием. Обучаясь на математическом факультете, он заинтересовался записями лекций американских психотерапевтов Фрица Перлза и Вирджинии Сатир. Перлз в 40‑е годы отошёл от теории психоанализа и создал собственный метод гештальт‑терапии. Сатир была одним из основателей Института ментальных исследований в Пало‑Альто. В 1972 году она познакомилась с Бендлером и Гриндером и стала сотрудничать с ними.
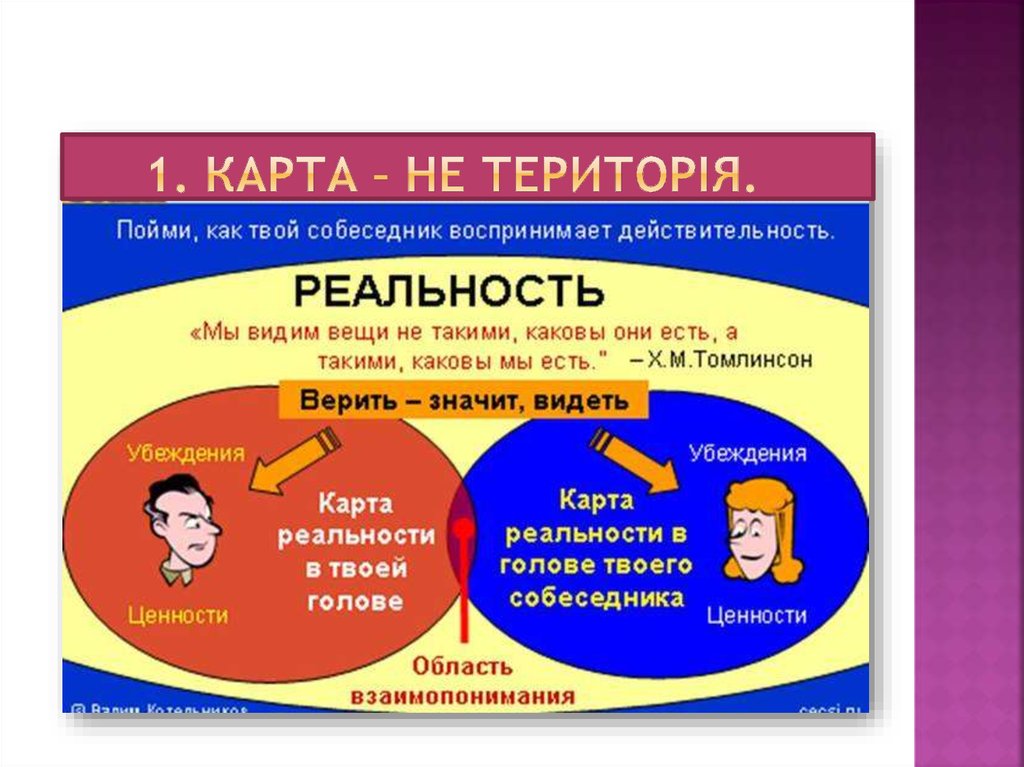
Также большое влияние на концепцию НЛП оказали взгляды Милтона Эриксона, Грегори Бейтсона и Альфреда Коржибски. Эриксон исследовал терапевтическое воздействие гипноза. Его речевые гипнотические модели вошли в НЛП под названием «модели Милтона». Бейтсон, британо‑американский антрополог, занимался изучением природы познания и человека. Его образ мышления стал одним из эталонов для создателей НЛП. Коржибски — лингвист, основатель общей семантики, науки о значении слов. Он первым употребил термин «нейролингвистический». Его утверждение «Карта ещё не территория» является одним из главных положений НЛП.
Эриксон исследовал терапевтическое воздействие гипноза. Его речевые гипнотические модели вошли в НЛП под названием «модели Милтона». Бейтсон, британо‑американский антрополог, занимался изучением природы познания и человека. Его образ мышления стал одним из эталонов для создателей НЛП. Коржибски — лингвист, основатель общей семантики, науки о значении слов. Он первым употребил термин «нейролингвистический». Его утверждение «Карта ещё не территория» является одним из главных положений НЛП.
Но вернёмся к Бендлеру. Он, увлёкшись психотерапией, стал копировать поведение Перлза и Сатир и ощутил, что может оказывать воздействие на людей: убеждать их в своей правоте, находить общий язык. Бендлер открыл свою школу, и его деятельностью заинтересовался профессор лингвистики в Калифорнийском университете Гриндер. Вместе они стали создавать концепцию НЛП. Свои наработки Бендлер и Гриндер изложили в двух частях книги The Structure of Magic (1975).
Эффект применения НЛП его создатели назвали терапевтической магией. Достаточно быстро концепция и основанные на ней тренинги стали приносить им большие деньги.
Достаточно быстро концепция и основанные на ней тренинги стали приносить им большие деньги.
В начале 80‑х годов Бендлер и Гриндер повздорили, и их пути разошлись. Они продолжили развивать концепцию, но каждый по‑своему.
Как НЛП должно работать, по мнению его создателей
Сторонники НЛП верят, что оно формирует:
- способы постановки и достижения целей;
- умение найти мотивацию;
- рецепты самосовершенствования;
- навыки находить общий язык;
- способность управлять людьми;
- методы объективной оценки окружающего мира и самого себя.
Главным способом достижения этих целей последователи НЛП считают умение правильно воспринимать и использовать поступающие в мозг сведения.
Считается, что каждый человек имеет предпочтительный метод обработки информации: визуальный (зрение), аудиальный (слух) или кинестетический (язык тела). Чтобы достичь успеха, нужно стать суперкоммуникатором, то есть научиться чередовать их все. Сделать же это можно, копируя поведение суперкоммуникаторов, абстрагируясь и научившись видеть ситуацию с противоположной стороны. С этим связаны понятия «метапрограммы», то есть фильтры информации, и «категоризация» — структурирование больших объёмов данных.
С этим связаны понятия «метапрограммы», то есть фильтры информации, и «категоризация» — структурирование больших объёмов данных.
Особое место в НЛП уделяется невербальной коммуникации: образам, интонации, жестам и мимике. Сторонники нейролингвистического программирования считают, что на неё приходится 93% человеческого общения, при этом больше половины отводится на язык тела, а слова составляют только 7%.
Психолингвисты считают, что на невербальные средства приходится 60–80% коммуникации.
Другой важный компонент НЛП — это убеждение о том, что подсознание побеждает сознание. Этим сторонники концепции объясняют необходимость работы над собой на «примитивном уровне» бессознательного. Проще говоря, они верят, что если вы скопируете привычки, жесты, осанку и манеры успешного человека, то остальное подтянется само собой.
Немного теории
В концепции нейролингвистического программирования используется много непонятных терминов, однако их довольно легко заменить обычными словами.
Например, значимую роль в НЛП играют пресуппозиции. Это установки в форме афоризма, не всегда связанные с реальностью. Часто они основаны на мировоззрении и научных взглядах Коржибски, Бейтсона и Сатир. Известным примером пресуппозиции НЛП является фраза Коржибски «Карта не территория, слово не предмет». То есть слово «собака» — это всё то, что вы знаете и думаете о собаках, а не само животное.
Также популярными у сторонников нейролингвистического программирования являются убеждения о том, что:
- тело и сознание взаимосвязаны;
- причиной любого действия является позитивное намерение;
- нет поражений, есть опыт.
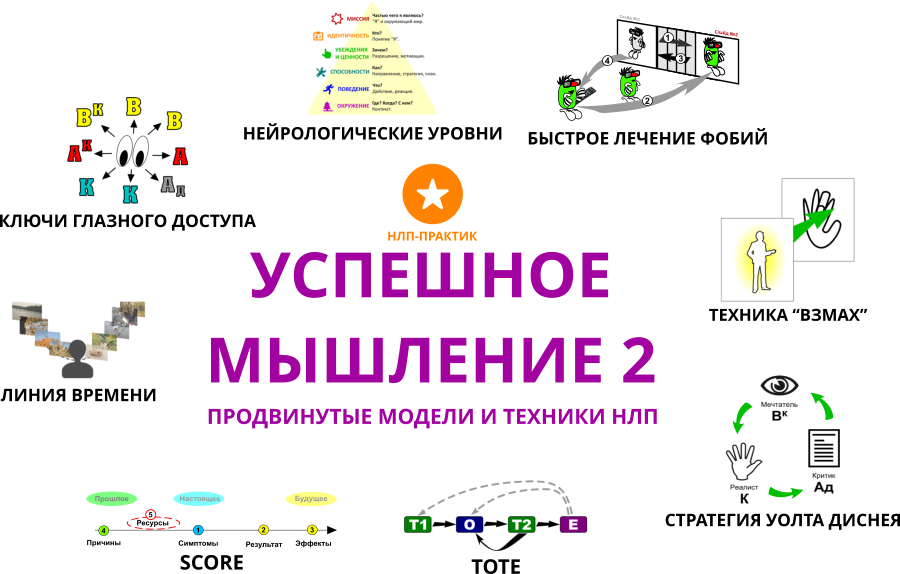
Часто в связи с НЛП упоминается модель TOTE (test — operation — test — exit). Она предполагает, что человек для достижения цели повторяет рутинные операции (действие и сверка с образцом).
Ещё сторонники НЛП используют гипноз и самогипноз, а также верят в комплексную латерализацию мозга — жёсткое различие функций полушарий и невозможность их замещения. Такой взгляд не соответствует представлениям современной науки, так как доказано, что при необходимости (в случае травмы или заболевания) различные его области способны брать на себя функции других.
Такой взгляд не соответствует представлениям современной науки, так как доказано, что при необходимости (в случае травмы или заболевания) различные его области способны брать на себя функции других.
Узнайте больше 👻
- Что такое гипноз и как его используют
Техники НЛП
В НЛП применяются индивидуальные и групповые упражнения вроде подстройки под позу, спора в одинаковых положениях тела и демонстрации. В них используются различные техники. Несмотря на сложные названия, они достаточно просты. Вот некоторые из них.
- Создание якоря — стимула, провоцирующего нужную реакцию или поведение. В качестве якоря используются вкусовые, цветовые, обонятельные ассоциации, которые срабатывают как условный рефлекс и направляют поведение человека в нужную сторону.
- Использование репрезентативных систем — воображения и чувственного опыта.

- Ассоциация и диссоциация — соотнесение себя с кем‑либо и независимый взгляд на себя со стороны.
- Моделирование — поиск ответа на вопрос, как успешные люди достигают поставленных целей, основа НЛП.
- Следование и ведение — копирование жестов, поз.
- Притягательное будущее (репрезентация) — представление чего‑либо настолько реалистично, что оно воплощается в действительность.
- Фрейминг и рефрейминг — установка чётких границ, помогающих достичь желаемого, и взгляд на себя с другой стороны («Я слишком ленив. Зато не делаю лишних ошибок»).
- Осознание экологической роли — изучение возможных последствий деятельности человека, установление причинно‑следственных связей.
- Стратегия Уолта Диснея — применение трёх ролей в командной работе для достижения результата: мечтатель придумывает различные варианты решения проблемы, в том числе нереалистичные, критик оценивает их ценность и находит слабые места, реалист составляет конкретные шаги.
- Использование метамоделей — трёх уровней осмысления опыта: вычёркивания, генерализации (широких универсальных формулировок), искажения (игнорирования части информации).
- Перцептивные позиции — разные точки зрения: от первого лица, от лица другого человека, от лица «мухи на стене» или «внутреннего мудреца».
Будьте начеку 🙆♂️
- К каким последствиям приводят тренинги для мужчин
Почему на самом деле НЛП не работает
Научная критика
Некоторые психотерапевты используют НЛП для лечения страхов, фобий, беспокойства, низкой самооценки, стресса, посттравматических синдромов, алкогольной и наркотической зависимостей, а также других психологических проблем. Результаты у такой терапии неоднозначны. НЛП не является строго научной методикой, как, например, когнитивно‑поведенческая терапия, и опытов, подтверждающих, что оно работает, практически нет.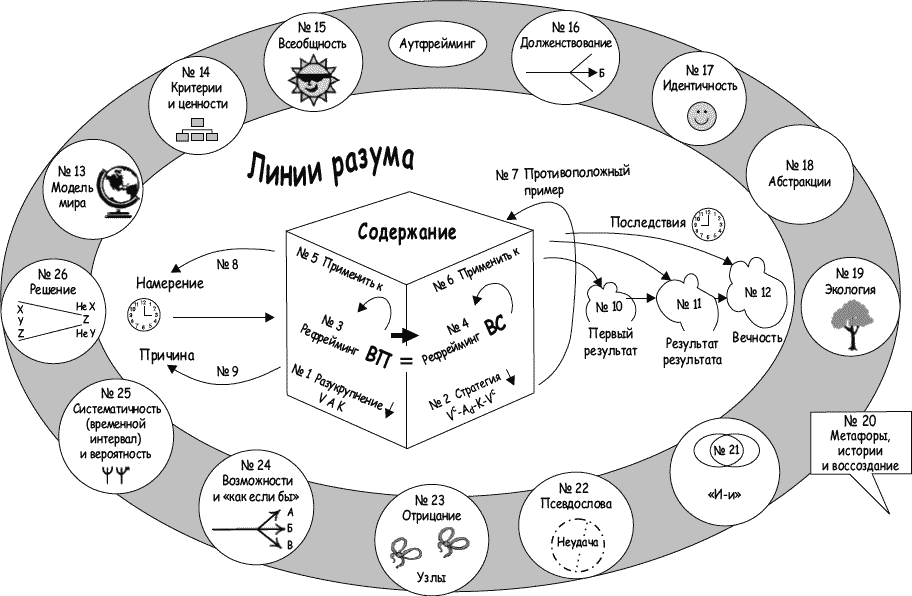
В 2012 году британские психиатры опубликовали результаты исследования эффективности практик НЛП. Они были в целом положительными, но специалисты пришли к выводу, что влияние нейролингвистического программирования на психологическое здоровье недостаточно изучено.
Чуть более оптимистичные для сторонников НЛП результаты получили голландские психологи в 2016 году. После однократного сеанса нейролингвистического программирования 64% пациентов с несерьёзными психологическими нарушениями сообщили об улучшении своего душевного состояния. В эксперименте участвовали 25 человек. Тем не менее, учёные из Нидерландов рекомендовали дальнейшее изучение методики НЛП.
Гораздо больше учёных выступают с критикой нейролингвистического программирования. Ещё в 2004 году профессор Университета Джорджа Мэйсона Дэниэл Дракман опубликовал исследование, проведённое по заказу армии США. В нём он заключил, что методы НЛП не работают.
В 2010 году польский психолог и автор научных книг Томаш Витковски отобрал из 315 статей о нейролингвистическом программировании 63, опубликованные в журналах из рейтинга международного научного индексирования (ISI), и проанализировал выводы из них. Только в 18,2% исследований подтверждается эффективность НЛП. 27,3% опубликовали неопределённые результаты. Большая же часть (54,5%) опровергают концепцию.
Только в 18,2% исследований подтверждается эффективность НЛП. 27,3% опубликовали неопределённые результаты. Большая же часть (54,5%) опровергают концепцию.
В 2014 году вышло исследование сотрудников Канадского агентства по лекарствам и технологиям в здравоохранении. Они пришли к выводу, что НЛП не помогает при лечении посттравматического, тревожного и стрессового расстройств.
Скептики указывают, что последователи НЛП используют устаревшие представления об устройстве мозга, допускают фактологические ошибки, применяют псевдонаучную терминологию. За почти полвека существования нейролингвистического программирования ни одного серьёзного исследования, подтверждающего его эффективность, не появилось.
Мария Николаева
Специалист по философии, автор книг по социологии, восточным психотехникам, преподаватель, переводчик, исследователь.
Неэффективность НЛП связана прежде всего с примитивизацией человеческой психики, реакции которой пытаются свести к компьютерной технологии, то есть «программированию». Но если любая программа для ПК, даже самая сложная, просчитывается до малейшего шага, то свобода воли человека позволяет ему делать совершенно непредсказуемые ходы.
Но если любая программа для ПК, даже самая сложная, просчитывается до малейшего шага, то свобода воли человека позволяет ему делать совершенно непредсказуемые ходы.
Попытки свести человеческое поведение к биокомпьютеру и взяться за его перепрограммирование не могут увенчаться успехом точно так же, как никакой искусственный интеллект в обозримом будущем не сможет заменить творческую личность. Все подобные перспективы остаются лишь научной фантастикой, но не становятся наукой. Именно так и нужно понимать пользу НЛП — как поучительную утопию, которая лишь подчёркивает отличие реальности как таковой.
НЛП и секты
Антропология и социология относят НЛП к явлениям нью‑эйджа, или религий нового века. Проще говоря, к сектам. В частности, утверждается, что последователи сект используют методы НЛП для обращения людей. Тимоти Лири в книге «Технологии изменения сознания в деструктивных культах» указывает, что для вербовки новых членов секты используют нейролингвистический рефрейминг и методики погружения в гипнотический транс.
В целом НЛП — продукт своего времени. Сравнение с нью‑эйджем не случайно: нейролингвистическое программирование появилось в одну эпоху с религиями нового века. Исследователь сект и культов Джозеф Хант назвал НЛП альтернативой саентологии. Тот же Бендлер, персонаж абсолютно в духе той эпохи, был наркоманом и проходил подозреваемым в деле об убийстве.
Что в итоге
Концепция НЛП скомпрометирована заигрыванием с наукой, хотя сама она ею не является, заумной терминологией, скрывающей простые мотивационные установки, и безумной коммерциализацией. Часто исследования с положительными результатами публикуют психологи, которые сами практикуют НЛП. Его успехи, очевидно, граничат со статистической погрешностью.
Нейролингвистическое программирование не работает даже с точки зрения логики: скопировав бессознательное поведение человека, мы не можем скопировать его знания, умения и навыки. Не позволяйте себя обмануть.
Читайте также 🧐
- «Целительница долго на меня смотрела, потом ходила вокруг со свечой».
 Как лечат знахари и к чему это приводит
Как лечат знахари и к чему это приводит - Есть ли у воды память? Разбираемся, как возник популярный миф и почему наука его опровергает
- 8 типов учителей, которым не стоит верить
- «А мне помогает»: почему столько людей продолжают верить в гомеопатию
- Чему учат на женских тренингах
Как определить и перевести языки для проекта НЛП | Дэвис Дэвид
От текстовых данных с несколькими языками к одному языку
Изображение PublicDomainPictures с Pixabay Эта статья была обновлена 20 июня 2022 г. вот
вот
С новым годом тебя, 2021 уже здесь и ты это сделал 💪 . 2020 год уже позади, и хотя 2020 год был трудным и странным для многих людей во всем мире, нам еще многое предстоит отпраздновать. В 2020 году я узнал, что все, что нам нужно, — это любовь и поддержка наших близких, членов семьи и друзей.
«Перед лицом невзгод у нас есть выбор. Мы можем быть горькими, или мы можем быть лучше. Эти слова — моя путеводная звезда». — Кэрин Салливан,
. Это будет моя первая статья в 2021 году, и я расскажу о некоторых языковых проблемах, с которыми может столкнуться специалист по данным или инженер по машинному обучению, работая над проектом НЛП, и о том, как вы можете решить их.
Представьте, что вы специалист по данным, которому поручено работать над проектом НЛП для анализа того, что люди публикуют в социальных сетях (например, Twitter) о covid-19.. Одна из ваших первых задач — найти разные хэштеги для COVID-19 (например, #covid19 ), а затем начать собирать все твиты, связанные с covid-19.
Когда вы начнете анализировать собранные данные, связанные с covid-19, вы обнаружите, что данные генерируются на разных языках мира, таких как английский, суахили, испанский , китайский, хинди и т. д. В этом случае у вас будет две проблемы, которые нужно решить, прежде чем вы начнете анализировать набор данных, первая — определяет язык конкретных данных, а второе — как вы можете перевести данные на язык по вашему выбору (например, все данные должны быть на английском языке).
Итак, как мы можем решить эти две проблемы?
Изображение Tumisu с сайта PixabayПервая проблема: определение языка
Первая проблема заключается в том, чтобы узнать, как определить язык для конкретных данных. В этом случае вы можете использовать простой пакет Python под названием обнаружение языка.
langdetect — это простой пакет Python, разработанный Михалом Данилаком, который поддерживает обнаружение 55 различных языков из коробки (коды ISO 639-1):
af, ar, bg, bn, ca, cs, cy, da, de, el, en, es, et, fa, fi, fr, gu, he,
hi, hr, hu, id, it, ja, kn, ko, lt, lv, mk, ml, mr , нэ, нл, нет, па, пл,
пт, ро, ру, ск, сл, со, кв, св, ув, та, тэ, й, тл, тр, ук, ур, ви, ж-сп, zh-tw
Установить langdetect
Чтобы установить langdetect, выполните следующую команду в своем терминале.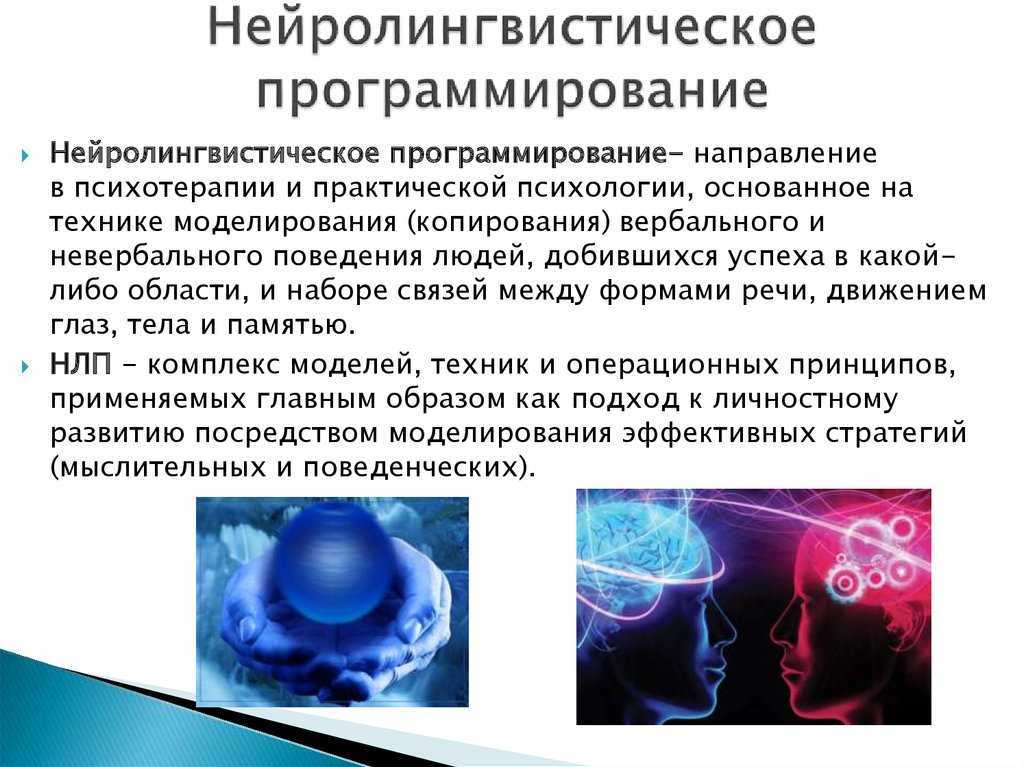
pip install langdetect
Базовый пример
Чтобы определить язык текста: например, « Tanzania ni nchi inayoongoza kwa utalii barani afrika ». Сначала вы импортируете метод обнаружения из langdetect, а затем передаете текст методу.
Вывод: «sw»
Метод определяет, что предоставленный текст написан на языке суахили («sw»).
Вы также можете узнать вероятности для лучших языков, используя метод detect_langs .
Вывод: [sw:0.9999971710531397]
ПРИМЕЧАНИЕ: Вам также необходимо знать, что алгоритм определения языка не является детерминированным, если вы запустите его на слишком коротком или слишком двусмысленном тексте, вы можете получить другой результаты каждый раз, когда вы запускаете его.
Вызовите следующий код перед определением языка, чтобы обеспечить согласованные результаты.
Теперь вы можете определить любой язык в ваших данных с помощью пакета Python langdetect.
Вторая проблема: языковой перевод
Вторая проблема, которую вам нужно решить, это перевести текст с одного языка на язык по вашему выбору. В этом случае вы будете использовать другой полезный пакет Python под названием google_trans_new .
google_trans_new — это бесплатный и неограниченный пакет Python, который реализует Google Translate API, а также выполняет автоматическое определение языка.
Установить google_trans_new
Чтобы установить google_trans_new, выполните в терминале следующую команду.
pip install google_trans_new
Простой пример
Чтобы перевести текст с одного языка на другой, необходимо импортировать класс google_translator из модуля google_trans_new . Затем вам нужно создать объект класса google_translator и, наконец, передать текст в качестве параметра методу translate и указать целевой язык с помощью параметра lang_tgt , например, lang_tgt=»en».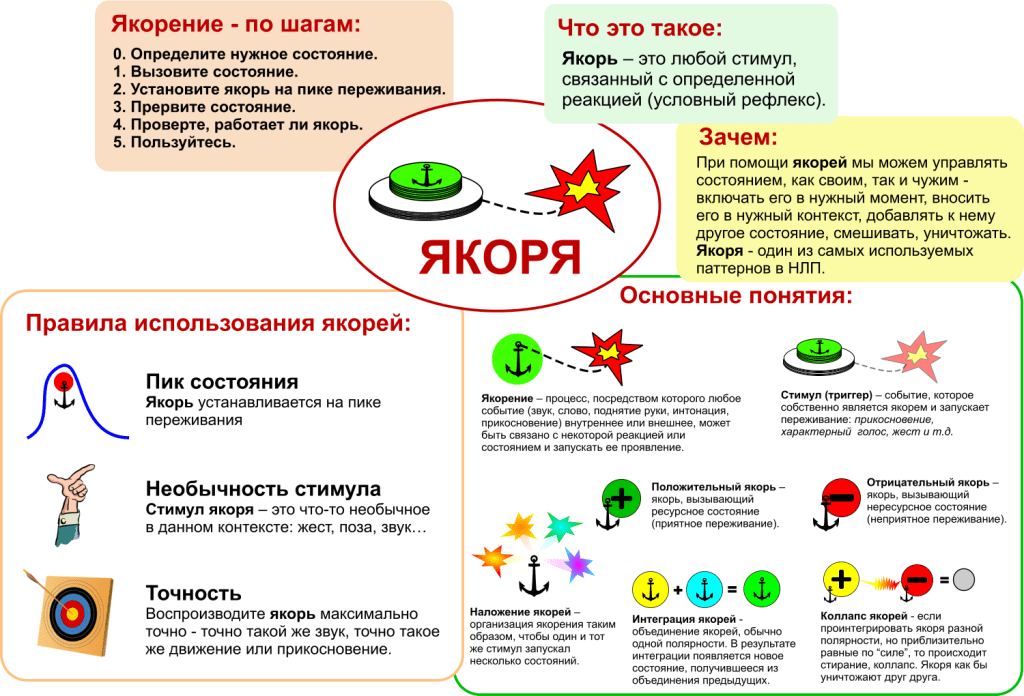
В приведенном выше примере мы переводим суахили предложение на английском языке . Вот результат после перевода.
Танзания — ведущая туристическая страна в Африке
По умолчанию метод translate() может определять язык предоставленного текста и возвращает ему английский перевод. Если вы хотите указать исходный язык текста, вы можете использовать параметр lang_scr .
Вот все названия языков вместе с их стенографическими обозначениями.
{'af': 'африкаанс', 'sq': 'албанский', 'am': 'амхарский', 'ar': 'арабский', 'hy': 'армянский', 'az': 'азербайджанский' , 'eu': 'баскский', 'be': 'белорусский', 'bn': 'бенгальский', 'bs': 'боснийский', 'bg': 'болгарский', 'ca': 'каталанский', ' ceb': 'cebuano', 'ny': 'chichewa', 'zh-cn': 'китайский (упрощенный)', 'zh-tw': 'китайский (традиционный)', 'co': 'корсиканский', ' hr': 'хорватский', 'cs': 'чешский', 'da': 'датский', 'nl': 'голландский', 'en': 'английский', 'eo': 'эсперанто', 'et' : 'эстонский', 'tl': 'филиппинский', 'fi': 'финский', 'fr': 'французский', 'fy': 'фризский', 'gl': 'галисийский', 'ka': ' грузинский», «de»: «немецкий», «el»: «греческий», «gu»: «гуджарати», «ht»: «гаитянский креольский», «ha»: «хауса», «haw»: «гавайский». ', 'iw': 'иврит', 'hi': 'хинди', 'hmn': 'хмонг', 'hu': 'венгерский', 'is': 'исландский', 'ig': 'igbo', 'id': 'индонезийский', 'ga': 'ирландский', 'it': 'итальянский', 'ja': 'японский', 'jw': 'яванский', 'kn': 'каннада', 'kk ': 'казахский', 'км': 'кхмерский', 'ко': 'корейский', 'ку': 'курдский (курманджи)', 'кы': 'киргизский', 'ло': 'лаосский', ' la': 'латинский', 'lv': 'латышский', 'lt': 'литовский', 'lb': 'люксембургский', 'mk': 'македонский', 'mg': 'малагасийский', 'ms' : «малайский», «мл»: «малаялам», «мт»: «мальтийский», «ми»: «маори», «г-н»: «маратхи», «мн»: «монгольский», «мой»: « Мьянма (бирманский)», «ne»: «непальский», «no»: «норвежский», «ps»: «пушту», «fa»: «персидский», «pl»: «польский», «pt»: 'португальский', 'pa': 'пенджаби', 'ro': 'румынский', 'ru': 'русский', 'sm': 'самоанский', 'gd': 'шотландский гэльский', 'sr': ' сербский», «st»: «сесото», «sn»: «шона», «sd»: «синдхи», «si»: «сингальский», «sk»: «словацкий», «sl»: «словенский» , 'so': 'сомали', 'es': 'испанский', 'su': 'сунданский', 'sw': 'суахили', 'sv': 'шведский', 'tg': 'таджикский', ' ta': 'тамильский', 'te': 'телугу', 'th': 'тайский', 'tr': 'турецкий', 'uk': 'украинский', 'ur': 'урду', 'уз' : 'узбекский', 'ви': 'вьетнамский', 'cy': 'валлийский', 'xh': 'коса', 'йи': 'идиш', 'йо': 'йоруба', 'зу': ' zulu', 'fil': 'филиппинец', 'he': 'иврит'}
', 'iw': 'иврит', 'hi': 'хинди', 'hmn': 'хмонг', 'hu': 'венгерский', 'is': 'исландский', 'ig': 'igbo', 'id': 'индонезийский', 'ga': 'ирландский', 'it': 'итальянский', 'ja': 'японский', 'jw': 'яванский', 'kn': 'каннада', 'kk ': 'казахский', 'км': 'кхмерский', 'ко': 'корейский', 'ку': 'курдский (курманджи)', 'кы': 'киргизский', 'ло': 'лаосский', ' la': 'латинский', 'lv': 'латышский', 'lt': 'литовский', 'lb': 'люксембургский', 'mk': 'македонский', 'mg': 'малагасийский', 'ms' : «малайский», «мл»: «малаялам», «мт»: «мальтийский», «ми»: «маори», «г-н»: «маратхи», «мн»: «монгольский», «мой»: « Мьянма (бирманский)», «ne»: «непальский», «no»: «норвежский», «ps»: «пушту», «fa»: «персидский», «pl»: «польский», «pt»: 'португальский', 'pa': 'пенджаби', 'ro': 'румынский', 'ru': 'русский', 'sm': 'самоанский', 'gd': 'шотландский гэльский', 'sr': ' сербский», «st»: «сесото», «sn»: «шона», «sd»: «синдхи», «si»: «сингальский», «sk»: «словацкий», «sl»: «словенский» , 'so': 'сомали', 'es': 'испанский', 'su': 'сунданский', 'sw': 'суахили', 'sv': 'шведский', 'tg': 'таджикский', ' ta': 'тамильский', 'te': 'телугу', 'th': 'тайский', 'tr': 'турецкий', 'uk': 'украинский', 'ur': 'урду', 'уз' : 'узбекский', 'ви': 'вьетнамский', 'cy': 'валлийский', 'xh': 'коса', 'йи': 'идиш', 'йо': 'йоруба', 'зу': ' zulu', 'fil': 'филиппинец', 'he': 'иврит'} Функция обнаружения и перевода Python
Я создал простую функцию Python, с помощью которой вы можете выполнять как обнаружение, так и перевод текста на выбранный вами язык.
Функция Python получает в качестве параметров текст и целевой язык. Затем он определяет язык предоставленного текста, и если язык текста совпадает с целевым языком, он возвращает тот же текст, но не тот же, он переводит предоставленный текст на целевой язык.
Пример:
В приведенном выше исходном коде мы переводим предложение на язык суахили. Вот результат: —
Natumai kwamba, nitakapojiwekea akiba, nitaweza kusafiri kwenda Mexico
В этой статье вы узнали, как решить две языковые проблемы, когда у вас есть текстовые данные на разных языках, и вы хотите перевести данные в один язык по вашему выбору.
Поздравляем 👏, вы дочитали до конца этой статьи!
Вы можете скачать блокнот, использованный в этой статье, здесь: https://github.com/Davisy/Detect-and-Translate-Text-Data
Если вы узнали что-то новое или вам понравилось читать эту статью, поделитесь ею, чтобы другие могу это увидеть. А пока, увидимся в следующем посте! Со мной также можно связаться в Твиттере @Davis_McDavid.
И последнее: Читайте другие подобные статьи по следующим ссылкам.
Как развернуть вашу модель НЛП в производство в качестве API с помощью Algorithmia
Простой способ шаг за шагом развернуть модель НЛП на бессерверном производстве.
medium.com
Как использовать Texthero для подготовки текстового набора данных для вашего проекта НЛП
Простой набор инструментов Python для быстрой и легкой работы с текстовым набором данных.
chatbotslife.com
Знакомьтесь с победителями конкурса новостей суахили по классификации
Первый виртуальный хакатон НЛП Zindi Africa посвящен африканским языкам.
davis-david.medium.com
Нейронный машинный перевод | Машинный перевод в НЛП
Введение
«Если вы говорите с человеком на языке, который он понимает, это ударит ему в голову. Если вы разговариваете с ним на его родном языке, это трогает его сердце».
– Нельсон Мандела
Красота языка не знает границ и культур. Изучение языка, отличного от нашего родного языка, является огромным преимуществом. Но путь к двуязычию или многоязычию часто может быть долгим и бесконечным.
Так много мелких нюансов, что мы теряемся в море слов. Однако с сервисами онлайн-перевода все стало намного проще (я смотрю на вас, Google Translate!).
Я всегда хотел выучить какой-нибудь другой язык, кроме английского. Я попробовал свои силы в изучении немецкого (или немецкого) еще в 2014 году. Это было весело и сложно. В конце концов мне пришлось уйти, но я затаил желание начать снова.
Перенесемся в 2019 год. Мне повезло, что я могу создать языковой переводчик для любой возможной пары языков. Каким благом была обработка естественного языка!
В этой статье мы рассмотрим этапы создания модели перевода с немецкого на английский язык с помощью Keras. Мы также бросим быстрый взгляд на историю систем машинного перевода, оглядываясь назад.
В этой статье предполагается, что вы знакомы с RNN, LSTM и Keras. Ниже пара статей, чтобы узнать о них больше:
- Введение в рекуррентные нейронные сети
- Введение в долговременную память
Содержание
- Машинный перевод — краткая история
- Понимание постановки задачи
- Введение в прогнозирование от последовательности к последовательности
- Реализация на Python с использованием Keras
Машинный перевод — краткая история
Большинство из нас познакомились с машинным переводом, когда Google придумал эту услугу. Но концепция существует с середины прошлого века.
Исследовательская работа в области машинного перевода (МТ) началась еще в 1950-х годах, в основном в Соединенных Штатах. Эти ранние системы опирались на огромные двуязычные словари, закодированные вручную правила и универсальные принципы, лежащие в основе естественного языка.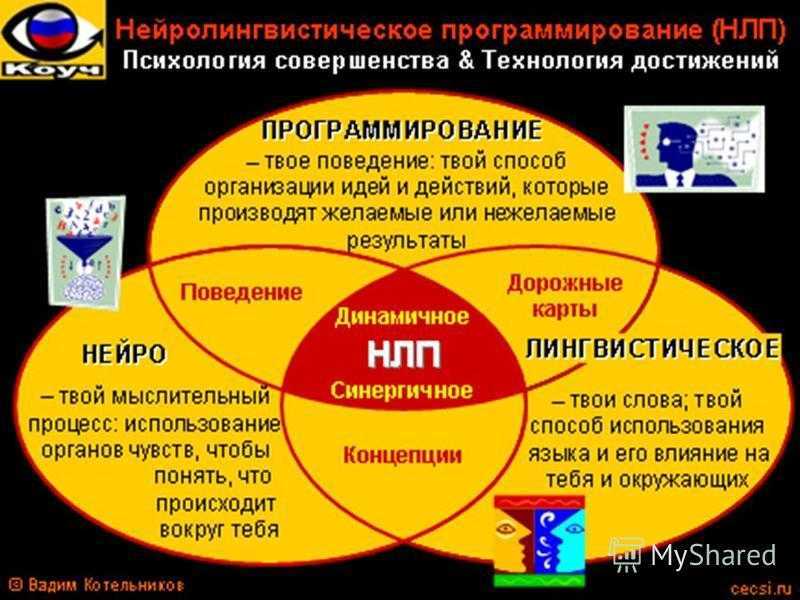
В 1954 году IBM впервые провела публичную демонстрацию машинного перевода. У системы был довольно маленький словарный запас, всего 250 слов, и она могла перевести только 49 отобранных русских предложений на английский язык. Сейчас это число кажется ничтожным, но многие считают эту систему важной вехой в развитии машинного перевода.
Это изображение взято из исследовательской работы, описывающей систему IBM
.Вскоре возникли две школы мысли:
- Эмпирические методы проб и ошибок с использованием статистических методов и
- Теоретические подходы, связанные с фундаментальными лингвистическими исследованиями
В 1964 году правительство США создало Консультативный комитет по автоматической обработке языков (ALPAC) для оценки прогресса в области машинного перевода. ALPAC провел небольшую проверку и опубликовал отчет 19 ноября.66 о состоянии МТ. Ниже приведены основные моменты этого отчета:
- Это подняло серьезные вопросы о возможности машинного перевода и назвало его безнадежным
- Финансирование исследования МТ не рекомендуется
- Это был довольно удручающий отчет для исследователей, работающих в этой области
- Большинство из них ушли с поля и начали новую карьеру
Не самая лучшая рекомендация!
За этим жалким отчетом последовал долгий засушливый период. Наконец, в 1981 в Канаде была развернута новая система под названием METEO System для перевода прогнозов погоды, выпущенных на французском языке, на английский язык. Это был довольно успешный проект, который просуществовал до 2001 года.
Наконец, в 1981 в Канаде была развернута новая система под названием METEO System для перевода прогнозов погоды, выпущенных на французском языке, на английский язык. Это был довольно успешный проект, который просуществовал до 2001 года.
Первый в мире инструмент веб-перевода, Babel Fish , был запущен поисковой системой AltaVista в 1997 году.
А затем произошел прорыв, с которым мы все теперь знакомы – Google Translate. С тех пор это изменило то, как мы работаем (и даже учимся) с разными языками.
Источник: translate.google.com
Понимание постановки задачи
Давайте вернемся к тому, на чем мы остановились во вводной части, то есть к изучению немецкого языка. Однако на этот раз я собираюсь заставить свою машину выполнять эту задачу. Цель состоит в том, чтобы преобразовать предложение на немецком языке в его аналог на английском языке с помощью системы нейронного машинного перевода (NMT).
Мы будем использовать данные о парах предложений на немецком и английском языках с http://www.manythings.org/anki/. Вы можете скачать его отсюда.
Введение в моделирование последовательностей (Seq2Seq)
МоделиSequence-to-Sequence (seq2seq) используются для различных задач NLP, таких как суммирование текста, распознавание речи, моделирование последовательности ДНК и другие. Наша цель состоит в том, чтобы перевести заданные предложения с одного языка на другой.
Здесь и ввод, и вывод являются предложениями. Другими словами, эти предложения представляют собой последовательность слов, входящих и выходящих из модели. Это основная идея моделирования Sequence-to-Sequence. Рисунок ниже пытается объяснить этот метод.
Типичная модель seq2seq состоит из 2 основных компонентов –
а) энкодер
б) декодер
Обе эти части, по сути, представляют собой две разные модели рекуррентной нейронной сети (RNN), объединенные в одну гигантскую сеть:
Я перечислил несколько важных вариантов использования моделирования Sequence-to-Sequence ниже (помимо машинного перевода, конечно):
- Распознавание речи
- Извлечение сущности/темы имени для определения основной темы из основного текста
- Классификация отношений для обозначения отношений между различными объектами, отмеченными на шаге выше
- Навыки чат-бота для общения и взаимодействия с клиентами
- Суммирование текста для создания краткой сводки большого объема текста
- Системы ответов на вопросы
Реализация на Python с использованием Keras
Пора замарать руки! Нет лучшего чувства, чем изучать тему, видя результаты из первых рук. Мы запустим нашу любимую среду Python (в моем случае Jupyter Notebook) и приступим к делу.
Мы запустим нашу любимую среду Python (в моем случае Jupyter Notebook) и приступим к делу.
Импорт необходимых библиотек
строка импорта
импортировать повторно
из массива импорта numpy, argmax, random, take
импортировать панд как pd
из keras.models импорт последовательный
из keras.layers импортировать Dense, LSTM, Embedding, RepeatVector
из keras.preprocessing.text импортировать Tokenizer
из keras.callbacks импортировать ModelCheckpoint
из keras.preprocessing.sequence импортировать pad_sequences
из keras.models импортировать load_model
от оптимизаторов импорта keras
импортировать matplotlib.pyplot как plt
%matplotlib встроенный
pd.set_option('display.max_colwidth', 200)
Чтение данных в нашу IDE
Наши данные представляют собой текстовый файл (.txt) с парами предложений на английском и немецком языках. Сначала мы прочитаем файл, используя функцию, определенную ниже.
Код Python:
Теперь мы можем использовать эти функции для чтения текста в массив в желаемом формате.
данные = read_text("deu.txt")
deu_eng = to_lines(данные)
deu_eng = массив (deu_eng)
Фактические данные содержат более 150 000 пар предложений. Однако мы будем использовать только первые 50 000 пар предложений, чтобы сократить время обучения модели. Вы можете изменить это число в соответствии с вычислительной мощностью вашей системы (или если вам повезет!).
deu_eng = deu_eng[:50000,:]
Предварительная обработка текста
Довольно важный шаг в любом проекте, особенно в НЛП. Данные, с которыми мы работаем, чаще всего неструктурированы, поэтому есть определенные вещи, о которых нам нужно позаботиться, прежде чем переходить к части построения модели.
(а) Очистка текста
Давайте сначала посмотрим на наши данные. Это поможет нам решить, какие шаги предварительной обработки следует предпринять.
deu_eng
массив([['Привет.', 'Привет!'],
['Привет', 'Grüß Gott!'],
['Беги!', 'Лауф!'],
. ..,
['У Мэри очень длинные волосы.', 'Maria hat sehr langes Haar.'],
["Мэри - секретарь Тома", "Мария и Томс Секретарин"],
['Мария - замужняя женщина', 'Maria ist eine verheiratete Frau.']],
dtype='
..,
['У Мэри очень длинные волосы.', 'Maria hat sehr langes Haar.'],
["Мэри - секретарь Тома", "Мария и Томс Секретарин"],
['Мария - замужняя женщина', 'Maria ist eine verheiratete Frau.']],
dtype='
Мы избавимся от знаков препинания, а затем переведем весь текст в нижний регистр.
# Удалить знаки препинания
deu_eng[:,0] = [s.translate(str.maketrans('', '', string.punctuation)) для s в deu_eng[:,0]]
deu_eng[:,1] = [s.translate(str.maketrans('', '', string.punctuation)) для s в deu_eng[:,1]]
deu_eng
массив([['Привет', 'Привет'],
['Привет', 'Grüß Gott'],
['Беги', 'Лауф'],
...,
['У Мэри очень длинные волосы', 'Maria hat sehr langes Haar'],
['Мэри - секретарь Тома', 'Мария ист Томс Секретарь'],
['Мария - замужняя женщина', 'Maria ist eine verheiratete Frau']],
dtype='
# преобразовать текст в нижний регистр
для i в диапазоне (len (deu_eng)):
deu_eng[i,0] = deu_eng[i,0]. lower()
deu_eng[i,1] = deu_eng[i,1].lower()
deu_eng
lower()
deu_eng[i,1] = deu_eng[i,1].lower()
deu_eng
массив([['привет', 'привет'],
['привет', 'grüß gott'],
['бежать', 'лауф'],
...,
['У Мэри очень длинные волосы', 'Мария Хэт Сер Лангес Хаар'],
['mary is toms secretary', 'maria ist toms sekretärin'],
['мэри - замужняя женщина', 'мария ist eine verheiratete frau']],
dtype='
(b) Преобразование текста в последовательность
Модель Seq2Seq требует, чтобы мы преобразовывали как входные, так и выходные предложения в целочисленные последовательности фиксированной длины.
Но прежде чем мы это сделаем, давайте визуализируем длину предложений. Мы зафиксируем длину всех предложений в двух отдельных списках для английского и немецкого языков соответственно.
# пустые списки
eng_l = []
deu_l = []
# заполнить списки длинами предложений
для i in deu_eng[:,0]:
eng_l.append(len(i.split()))
для i в deu_eng[:,1]:
deu_l. append(len(i.split()))
length_df = pd.DataFrame({'eng':eng_l, 'deu':deu_l})
length_df.hist (ячейки = 30)
plt.show()
append(len(i.split()))
length_df = pd.DataFrame({'eng':eng_l, 'deu':deu_l})
length_df.hist (ячейки = 30)
plt.show()
Довольно интуитивно понятно – максимальная длина немецких предложений составляет 11, а английских фраз – 8.
Затем векторизуйте наши текстовые данные с помощью класса Keras Tokenizer() . Это превратит наши предложения в последовательности целых чисел. Затем мы можем дополнить эти последовательности нулями, чтобы сделать все последовательности одинаковой длины.
Обратите внимание, что мы подготовим токенизаторы как для немецких, так и для английских предложений:
# функция для сборки токенизатора
деф токенизация (строки):
токенизатор = токенизатор()
tokenizer.fit_on_texts(строки)
вернуть токенизатор
# подготовить английский токенизатор
eng_tokenizer = токенизация (deu_eng[:, 0])
eng_vocab_size = длина (eng_tokenizer.word_index) + 1
англ_длина = 8
print('Размер английского словаря: %d' % eng_vocab_size)
Английский словарный запас Размер: 6453
# подготовить токенизатор Deutch
deu_tokenizer = токенизация (deu_eng[:, 1])
deu_vocab_size = длина (deu_tokenizer. word_index) + 1
deu_length = 8
print('Размер немецкого словаря: %d' % deu_vocab_size)
word_index) + 1
deu_length = 8
print('Размер немецкого словаря: %d' % deu_vocab_size)
Немецкий словарь Размер: 10998
Приведенный ниже кодовый блок содержит функцию для подготовки последовательностей. Он также будет выполнять заполнение последовательности до максимальной длины предложения, как указано выше.
# последовательности кодирования и пэдов
def encode_sequences (токенизатор, длина, строки):
# целочисленные последовательности кодирования
seq = tokenizer.texts_to_sequences(строки)
# последовательности пэдов с 0 значениями
seq = pad_sequences (seq, maxlen = длина, заполнение = 'сообщение')
возврат последовательность
Модельное здание
Теперь мы разделим данные на обучающий и тестовый наборы для обучения и оценки модели соответственно.
из sklearn.model_selection импорта train_test_split
# разделить данные на обучающий и тестовый наборы
поезд, тест = train_test_split(deu_eng, test_size=0.2, random_state=12)
Пришло время кодировать предложения. Мы закодируем немецких предложений в качестве входных последовательностей и английских предложений в качестве целевых последовательностей . Это необходимо сделать как для обучающего, так и для тестового набора данных.
Мы закодируем немецких предложений в качестве входных последовательностей и английских предложений в качестве целевых последовательностей . Это необходимо сделать как для обучающего, так и для тестового набора данных.
# подготовить обучающие данные
trainX = encode_sequences (deu_tokenizer, deu_length, train [:, 1])
trainY = encode_sequences(eng_tokenizer, eng_length, train[:, 0])
# подготовить данные для проверки
testX = encode_sequences (deu_tokenizer, deu_length, test[:, 1])
testY = encode_sequences(eng_tokenizer, eng_length, test[:, 0])
Самое интересное!
Мы начнем с определения архитектуры нашей модели Seq2Seq:
- Для кодировщика мы будем использовать слой внедрения и слой LSTM
- Для декодера мы будем использовать еще один слой LSTM, за которым следует плотный слой
Архитектура модели
# сборка модели NMT
def define_model(in_vocab,out_vocab,in_timesteps,out_timesteps,единицы):
модель = Последовательный()
model. add (Встраивание (in_vocab, единицы измерения, input_length = in_timesteps, mask_zero = True))
model.add (LSTM (единицы))
model.add(RepeatVector(out_timesteps))
model.add (LSTM (единицы, return_sequences = True))
model.add (плотный (out_vocab, активация = 'softmax'))
вернуть модель
add (Встраивание (in_vocab, единицы измерения, input_length = in_timesteps, mask_zero = True))
model.add (LSTM (единицы))
model.add(RepeatVector(out_timesteps))
model.add (LSTM (единицы, return_sequences = True))
model.add (плотный (out_vocab, активация = 'softmax'))
вернуть модель
В этой модели мы используем оптимизатор RMSprop, так как обычно это хороший выбор при работе с рекуррентными нейронными сетями.
# сборка модели
модель = определить_модель (deu_vocab_size, eng_vocab_size, deu_length, eng_length, 512)
среднеквадратичных значений = оптимизаторы.RMSprop(lr=0,001)
model.compile (оптимизатор = rms, loss = 'sparse_categorical_crossentropy')
Обратите внимание, что мы использовали « sparse_categorical_crossentropy » в качестве функции потерь. Это связано с тем, что функция позволяет нам использовать целевую последовательность как есть, а не в формате горячего кодирования. Быстрое кодирование целевых последовательностей с использованием такого огромного словаря может занять всю память нашей системы.
Мы готовы приступить к обучению нашей модели!
Мы будем обучать его в течение 30 эпох и с размером пакета 512 с разделением проверки 20%. 80 % данных будут использоваться для обучения модели, а остальные — для ее оценки. Вы можете изменить и поиграть с этими гиперпараметрами.
Мы также будем использовать ModelCheckpoint() , чтобы сохранить модель с наименьшими потерями при проверке. Лично я предпочитаю этот метод ранней остановке.
имя файла = 'model.h2.24_jan_19'
контрольная точка = ModelCheckpoint (имя файла, монитор = 'val_loss', verbose = 1, save_best_only = True, режим = 'min')
# модель поезда
история = model.fit(trainX, trainY.reshape(trainY.shape[0], trainY.shape[1], 1),
эпохи = 30, batch_size = 512, validation_split = 0,2, обратные вызовы = [контрольная точка],
подробный=1)
Давайте сравним потери при обучении и при проверке.
plt. plot(история.история['потеря'])
plt.plot(история.история['val_loss'])
plt.legend(['поезд','проверка'])
plt.show()
plot(история.история['потеря'])
plt.plot(история.история['val_loss'])
plt.legend(['поезд','проверка'])
plt.show()
Как вы можете видеть на графике выше, потери при проверке перестали уменьшаться после 20 эпох.
Наконец, мы можем загрузить сохраненную модель и сделать прогнозы по невидимым данным — testX.
модель = load_model('model.h2.24_jan_19')
preds = model.predict_classes(testX.reshape((testX.shape[0],testX.shape[1])))
Эти прогнозы представляют собой последовательности целых чисел. Нам нужно преобразовать эти целые числа в соответствующие им слова. Давайте определим функцию для этого:
определение get_word(n, токенизатор):
для слова индекс в tokenizer.word_index.items():
если индекс == n:
возвратное слово
возврат Нет
Преобразование прогнозов в текст (английский):
предс_текст = []
для я в пред:
темп = []
для j в диапазоне (len (i)):
t = get_word(i[j], eng_tokenizer)
если j > 0:
если (t == get_word(i[j-1], eng_tokenizer)) или (t == None):
темп. добавлять('')
еще:
temp.append(t)
еще:
если (т == Нет):
темп.добавлять('')
еще:
temp.append(t)
preds_text.append(' '.join(temp))
добавлять('')
еще:
temp.append(t)
еще:
если (т == Нет):
темп.добавлять('')
еще:
temp.append(t)
preds_text.append(' '.join(temp))
Давайте поместим исходные английские предложения в тестовый набор данных и предсказанные предложения в фрейм данных:
pred_df = pd.DataFrame({'фактический': тест[:,0], 'прогнозируемый': preds_text})
Мы можем случайным образом распечатать некоторые фактические и предсказанные экземпляры, чтобы увидеть, как работает наша модель:
# напечатать 15 строк случайным образом
pred_df.sample(15)
Наша модель Seq2Seq отлично справляется со своей задачей. Но есть несколько случаев, когда он упускает из виду ключевые слова. Например, «я устал от бостона» переводится как «я в бостоне».
Это проблемы, с которыми вы будете регулярно сталкиваться в НЛП. Но это не непреодолимые препятствия. Мы можем смягчить такие проблемы, используя больше обучающих данных и создав лучшую (или более сложную) модель.